




This parrot is no more! He has ceased to be! He's expired and gone to meet his maker! He's a stiff! Bereft of life, he rests in peace! If you hadn't nailed him to the perch, he'd be pushing up the daisies! His metabolic processes are now history! He's off the twig! He's kicked the bucket, he's shuffled off his mortal coil, run down the curtain and joined the bleedin' choir invisible! THIS IS AN EX-PARROT!
— Monty Python, Series 1, Episode 8
For a while, some people dismissed language models as “stochastic parrots”. They said models could just memorise statistical patterns, which they would regurgitate back to users. A model was a simulacrum of intelligence: it would mimic patterns of intelligent thought, but never go beyond the data it had seen in training.
The problem with this theory, is that, alas, it isn’t true.
And fortunately for our purposes, exactly how the parrot ‘ceased to be’ is a good hook for explaining what’s going on inside language models.
If a language model was just a stochastic parrot, when we looked inside to see what was going on, we’d basically find a lookup table. The model would be embedding its input sequence (read: turning a string of words into a matrix) and running a search for the most similar pattern in its training data and copying this. But it doesn’t look like this. As we delve into the models, we find circuits. These are general algorithms that the model has made to solve classes of problems.
These circuits aren’t ‘laid out’ like how an electrician would wire a house or a programmer would write a program. They are more like an unholy tangle of wires. This is—counterintuitively—desirable! The goal of a model is to most efficiently represent all of the information and to generalise to solve problems. If the researchers had laid out how the model should achieve this, it would be more of a hindrance than a help. We want to “let the compute figure it out”.
What does this mean in practice? A model is a stack of layers that contain a sequence of mathematical operations. The researchers control the ‘settings’, like the number of layers in the model and the learning policy. The model learns its ‘weights’ (read: values for the mathematical operations). Through the complex interaction between weights, the models learn circuits. So the circuits are controlling how information flows through the layers.
This means circuits aren’t easy to spot. The first time they were seen in language models was December 2021, when Anthropic released a paper pointing to ‘induction heads’. These were a kind of attention head that could notice patterns in the input sequence and so, on the fly, the model could realise that it might need to recreate this pattern later. For the general class of problems—“recreate patterns found in the input”—this circuit could be reused for other patterns the model hadn’t seen in training. This is clearly more than the rote memorisation which AI sceptics had said language models were doing!
Until recently, the circuits that had been identified were limited to “toy-sized” models and often “algorithmic” tasks, not the full complex behaviour of large models that we care about. (For example, this induction heads paper had been on a two layer model.) This changed with a May 2024 paper from Anthropic, which developed a technique to elicit representations (read: sub-units of circuits) from much larger models. You might’ve seen this already, because they used their elicitation techniques to find a “Golden Gate Bridge” feature and develop a demo which had this always turned on. Whenever you gave this version of Claude a prompt, it would find a way to steer its answer towards the Golden Gate Bridge regardless of the original topic.
Their latest papers, from a couple of weeks ago, are extending this work to show how the model combines and relates these internal representations of features like “Golden Gate Bridge” to form circuits. The most important bit of this is that they elicit circuits for complex behaviours in large models. This proves that even in more complex situations than “patterns from the input”, the model isn’t just a giant lookup it is doing serious computation. The kind which generalises.
What did they do?
The researchers built a new tool for seeing which features are active at every layer of the model. This means we can see how and in what order the model considers different bits of information. This is called a “cross-layer transcoder”. You can think of it as a string of lights attached to each layer. When a light is on, it shows which feature is activated. The researchers use these lights to assemble “attribution graphs”.
The most interesting application, in my view, was to how the model is generating rhyming couplets. There are two ways you might imagine this happening: it either improvises word-by-word as it goes or it plans ahead. The researchers found the latter—once the model had generated the first line, it would “look ahead” to the end of the second line.
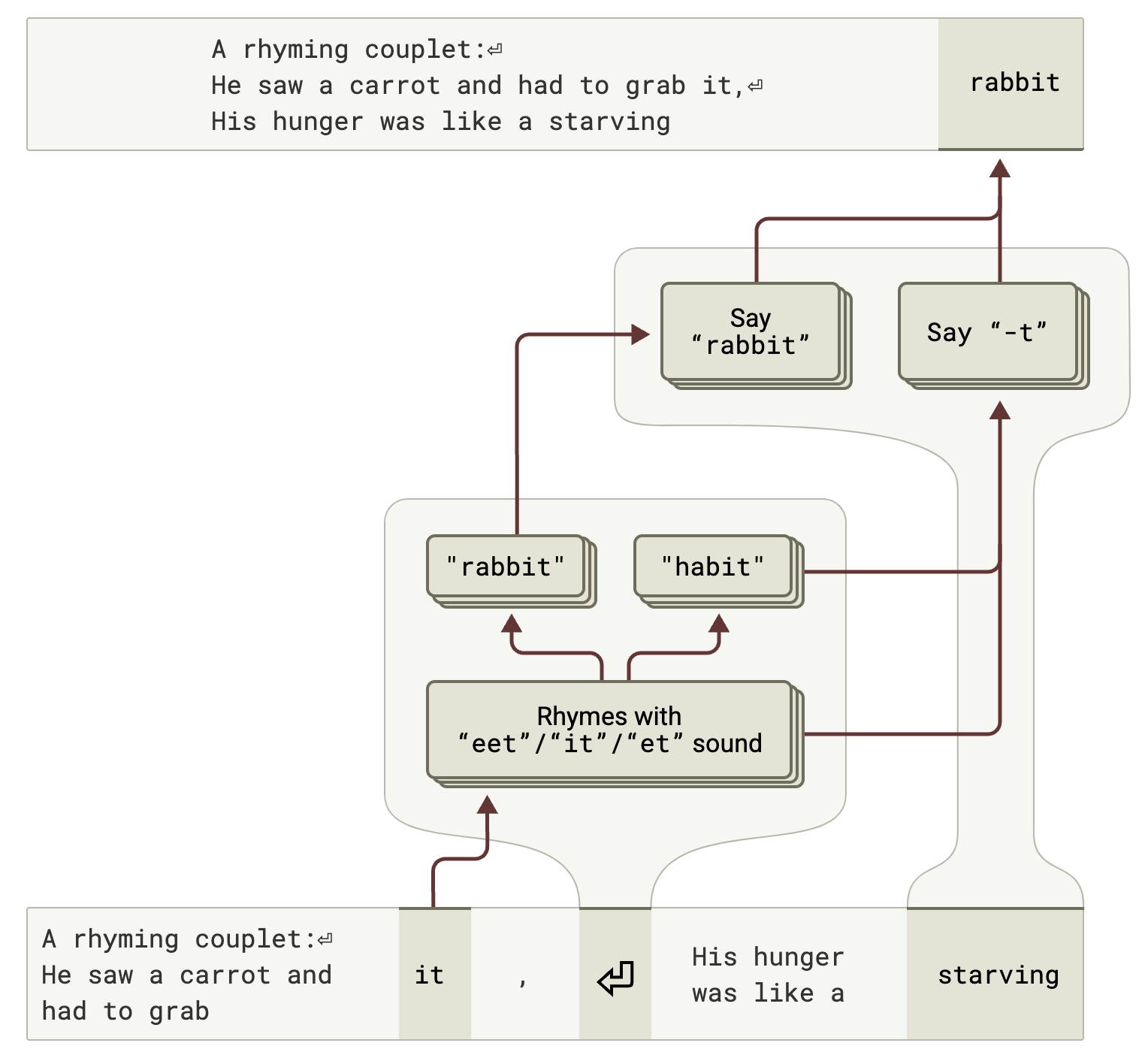
At the end of the first line (after the word “it”) the model would activate features which correspond to potential rhymes. In this case, “habit” or “rabbit” rhyme with “grab it”. The researchers perturbed the model activations to confirm the decision was actually happening at this point.
Next—and perhaps even more surprisingly—the model would use the final word it planned (“rabbit”) to plan the intermediate words. A group of “comparison features” were activated by the final word to analyse potential intermediates, so it was also looking backwards to create the structure of the line.
This kind of circuitry—to plan forwards and back—was learned by the model without explicit instruction; it just emerged from trying to predict the next word in other poems.
The challenge for research is that generalisation like this depends on seeing quite a lot of examples. Fortunately, there is a lot of poetry. The hypothesis we have for circuit formation is that initially, models are memorising a lookup table, but seeing enough examples causes the model to "privilege" the circuit rather than the table. The model realises its performance will be better from swapping to the general approach and thus, it seems like a circuit “snaps” into place. The paper includes some other examples where the model failed to make these generalisations because it hadn’t seen enough examples in those domains.
Where does this leave us?
The examples of generalisation are enough to prove the models are not stochastic parrots. But there are clearly limits to their circuitry. The more interesting version of the parrot debate is whether language models can generalise beyond circuits for ‘low level’ tasks they’ve seen in their training data? Have they learned the ability to solve entirely new problems from seeing a large and diverse enough set of problems during training. While they’ve learned the muscle for generating rhyming couplets in novel ways, could they have come up with the concept in the first place?
This is the essence of Francois Chollet’s critique of language models (and his motivation for creating the ARC-AGI benchmark): while they can learn circuits, the real test is whether they can generate new circuits on the fly to solve unfamiliar problems. From a Dwarkesh interview, Chollet says:
LLMs are very good at memorizing small static programs. They've got this sort of bank of solution programs. When you give them a new puzzle, they can just fetch the appropriate program and apply it. It looks like reasoning but it's not really doing any sort of on-the-fly program synthesis. All it's doing is program fetching.
You can actually solve all these benchmarks with memorization. If you look at the models and what you're scaling up here, they are big parametric curves fitted to a data distribution. They're basically these big interpolative databases, interpolative memories. Of course, if you scale up the size of your database and cram more knowledge and patterns into it, you are going to be increasing its performance as measured by a memorization benchmark.
That's kind of obvious. But as you're doing it, you are not increasing the intelligence of the system one bit. You are increasing the skill of the system. You are increasing its usefulness, its scope of applicability, but not its intelligence because skill is not intelligence. That's the fundamental confusion that people run into. They're confusing skill and intelligence.
Since this interview, models have made enormous progress on Chollet’s test. OpenAI’s o3 model, using a high-compute setting and finetuned on a training set, was able to score 87.5% while at the time of recording, the highest score was only 35%. What explains this improvement is unclear, however. It could have been using reasoning in the Chain of Thought, or better pre-training algorithms, though other people have suggested older models struggled to see the problems.
The open and important question is what degree of generalisation can we get in the circuitry. As the models get better, the pretraining algorithms get more sample efficient, and the Chain Of Thought’s get longer, we should probably imagine that generalisation to new problems get better. But how much?
What can we take away from the ‘stochastic parrot’ saga?
Despite what I’ve just said, I don’t think most of the “stochastic parrot” debate was ever really about circuitry.
The paper which coined the term was a work of social science, not an investigation into the model’s internal dynamics. Others carried the term forwards. “Stochastic parrots” became part of a broader set of arguments that were part of our desire to explain away the prospect of big change in the world. “Scaling is over”; “the reversal curse means AI is doomed to fail”; “they will hit the data wall”; “the energy-intensive approach isn’t the true way”; “reasoning will only work in code and math”, and so on.
I think it’s more than just avoiding change though: if it turned out that human intellect was the same as next-token prediction over the Internet, isn’t that a bit…dissapointing? Quite a lot of our story for what makes people special depends on Enlightenment ideas about our capacity for reason, our ability to make discoveries, and to use this for progress. If an AI system could do all this too, we'd be set adrift. This is especially so if the ideas are simple: people are sacred, so it follows that their intelligence be mystical and their computation sophisticated? Are we undermined if it is all just simple interpolation over short distances?
Perhaps it is our fault for attaching ourselves to a set of ideas we understand so poorly. What does it mean to reason? What does it mean to understand? What does it mean to be original? I don’t really know. As this essay puts it, perhaps “everything is the bar scene in Good Will Hunting” and we’re all stochastic parrots reciting obscure passages and contending things like a first year grad student. The essay concludes…
I guess my best answer to all this is to try to achieve a sort of meta-recognition of your own unoriginality, while still persisting in it. If you are a first-year grad student, and you find yourself making the contention of a first-year grad student, for fuck’s sake just stop, not least because language models can probably do it better and faster. But if you’ve taken into account your bounded experience, the determined nature of your reading and the limits to your self-expression, and you still think it’s worth putting on paper, then by all means, go ahead!
I think it’s a bit like conversation at parties; in my first year after university, we all talked about the same stuff - “are you enjoying your investment banking job? Oh, you went to bed at 3am last night? You’re also thinking of going to play for your old college rugby team next weekend?” Now, everyone’s like “Did you see they got engaged? I can’t believe it, she’s still so young; I’m so over Hinge dates, I just want my friend to introduce me to someone”; soon it’ll be, like, “I’m thinking of buying a house; maybe we’ve had enough of London, we just need more space”; I can just imagine the agonising over whether you should send your kids to private school. All of this is deeply unoriginal - determined entirely by our job, age, social status, location - and yet is it so bad? Maybe we should all just talk and write a bit more, and never mind what Will Hunting would say about it.
Whatever the answer is, we should probably start looking. (Or at least, I should—I’ve just told you about someone else’s research and someone else’s essay.) When powerful AI gets made, it’ll be an unwelcome look at our own specialness and we’ll need new and better ideas for what this is. These questions are still avoidable—AI isn’t changing that much yet—but at some point, we’ll have wished we started looking sooner.
The parrot is dead. Don’t be the shopkeeper.
Thanks to Theo Horsley for invaluable comments on drafts of this piece.
LLMs map social learning, not human individual intellect, not even en masse. The vectorspace magic is an aggregate ripped off from the social cues we use to innovate, that process arising up from individual invention and experience ( a bit like any photo uploaded to FB or other social media stripped of its meta-data and enters an aggregate algorithmic stupefaction engine).
That these LLMs in all their variety also shows us stuff we are not aware, especially in multi-modal avenues, or not-as-serial-processed-as-we-thought, of is no surprise, we just don't understand ourselves as a social learning species (we have not innovated a response to our self-domestication success stories). LLMs steal our social learning and some of us stupidly call that general intelliegence, that is our error. Claims of copyright infringement pale into insignificance beside that "theft".
https://whyweshould.substack.com/p/social-learning-101
Logic is a hindsight, LLMs map/mix/mash our hindsights.
It’s still a lookup table.
How l the internal machinations work don’t matter when, for any given input, a predetermined output is produced. The only reason LLMs (or other AI systems) don’t always give the same output in real world use is that randomness (‘heat’) is deliberately introduced.
In a very real sense, the model is ‘just’ compression of a lookup table.
Of course, maybe our intelligence is also just a representation of a lookup table at its base (the classic Chinese Room problem - or the question of ‘how can we have free will if the universe is deterministic?’).