


Will there be extreme inequality from AI?

There are two scenarios which some people fear could cause extreme inequality from AI.
The first is that automation causes some people’s wages to diverge dramatically from others. Some jobs involve leveraging AI, so the top performers can get paid a lot more than people doing work which doesn’t require AI.
The second is that, at some point, AI and robotics become capable of doing all tasks better than humans can. Humans would have to compete against faster, cheaper, ‘better’ machines, and would be unable to keep up. In this scenario, all of the income flows to the owners of capital and the humans who don’t own capital…err…wouldn’t do very well.
Economists would talk about these scenarios as ‘the distribution within labour’s share of income’ and ‘capital versus labour’s share of income’.
There is precedent for the first scenario—technologies have changed the structure of the labour market many times over—but the second scenario requires more first principles reasoning. I am broadly optimistic that we can achieve a good outcome in both scenarios.
How have previous technological revolutions affected labour markets?
We can categorise technologies by whether they are mainly a substitute for skilled labour, or a complement. To generalise, technologies of the 19th century were substituting for skilled labour. Power looms and spinning machines replaced artisanal weavers with lower-skilled machine operators. Machine tools and manufacturing displaced craftsmen in lots of goods production too. On the other hand, technologies of the 20th century were generally complements to skilled labour: jobs that were downstream of electrification typically required a high school-level education, while the jobs downstream of computerisation typically required college education.
The economists Claudia Goldin and Lawrence Katz have established a framework to explain income inequality in terms of the relative pace of technological development and educational attainment. (Their excellent book is aptly-named The Race Between Education and Technology.) To summarise, skill-biased technological change — like electricity and computers — is creating new demand for skill. In periods where technological development outpaces improvements in human capital, the pool of workers with suitable skills is growing slower than the demand for their skills. This means their wages rise relative to those without. Conversely, when the supply of skilled labour outpaces new demand for skill, the wage premium shrinks.
Goldin and Katz map this onto inequality through the 20th century. Inequality decreases for the first three quarters and rises in the final quarter, roughly to the level it began the period. This is congruent with periods of educational acceleration—the growth of the high school movement in the first third of the century, and the growth of state colleges following the GI bill—and periods of educational stagnation, from about 1970 onwards.
This educational expansion also explains why the 20th Century was the American Century. From much earlier in the century, the US was educating a greater portion of its citizens for longer than its European counterparts. In 1960, just 15% of British 17 year-olds were in full time education, while 69.5% of Americans in the same age group were graduating high school. US education was egalitarian, British education was elitist.
So technology, acting alone, doesn’t create labour market inequality. Technology is just the demand side of the equation. Education is the supply side.
How does this relate to AI?
AI creates an enormous demand for skill.
First, in using the models. There is huge variety in the quality of a model’s output depending on the usefulness of its prompt. Some people have strong intuition for where the models excel, how they can be pushed, and where they struggle.
At the moment, the models are limited by the horizon length they can act for. Deep Research can write a report in five or ten minutes that would take a human about four hours to assemble. But a recent paper from METR, a model evaluator, has shown that on a large suite of software engineering tasks the time horizon models can act for is doubling every seven months. Were this trend to continue, 2028’s agents would be able to act for a ‘week-equivalent’ of human work. 2030’s agents would be able to act for a ‘month-equivalent’. (Whether this can generalise outside of software engineering and when this might slow down is uncertain.)

But the general trend would provide enormous leverage to knowledge workers who know how to use the models best. A good intuition for this is the Archimedes line, “give me a lever long enough, and I will move the world”. Well, the length of the stick is doubling every seven months. As the manager of a team of agents, knowledge workers will decide what tasks to assign, provide context where the model lacks it, correct the model’s weaknesses and make taste-based decisions. This might feel like a “promotion for everyone”.
The second source of demand for skill will be in automating particular workflows. To automate a task, we have to build scaffolding for the agent to operate within. Part of this is technology-driven—the agents are too unreliable for unbounded environments—and part of this is business-need—companies want to get their agents to act in deterministic ways, with instructions about when to escalate to a human and so on. But a lot of this depends on having good quality data structure across the whole company. One of the reasons we might have seen fewer customer service agents than we might expect, given model capabilities, is that agents need to have suitable infrastructure to find the answers to the customer’s query. The plan is something like:
Complete the very difficult organisational change to manage the company’s information in a way that is legible to AI systems.
Step #1 is much harder than step #2! There will be, in the near term, incredible demand for people who have the skill to do #1 and have the know-how for #2.
Over time, the agents will need less of this kind of scaffolding. They will become more sample efficient, meaning they need to see fewer examples of a task before they can do it. They will have better memory, which limits their performance today. They will become more reliable, needing fewer guardrails. While they are not, humans will fill in the gaps.
How do we supply the skill to AI-driven demand?
One of the criticisms made of the Katz and Goldin book is that it can treat additional years of schooling and skill too monolithically. Whether additional years of education are actually improving skill to the degree we might hope is unclear. Work from the economist Bryan Caplan has shown that two thirds of the college wage premium is attributable to the signalling value of a degree, and just a third was attributable to human capital improvement. We can’t just spam the “more education” button and hope for better outcomes. At least in the UK, 50% of people are going to university already.
However, this is the first general-purpose technology that can help us improve directly. Electricity only very weakly helps to acquire skills for industrial production—perhaps by allowing you to read later into the night—but AI can be a tutor. The quality of education can be radically improved.
When it comes to inequality, an underrated concern for future wage differences would be that independent schools adopt AI tutoring much faster than state-funded schools. A recent news story highlighted a Texas private school which had been able to boost their test scores to the top 2% in the US. Someone I know who started an AI tutoring company is only selling to microschools in the US, because it would have been slower to sell to public school districts. OpenAI has created ChatGPTedu and partnered with individual universities and the California State system to provide free access to students, and Anthropic is doing something similar.
The UK’s national strategy seems to be to keep AI ‘teacher-facing’ in state schools.
Which jobs are most exposed to AI?
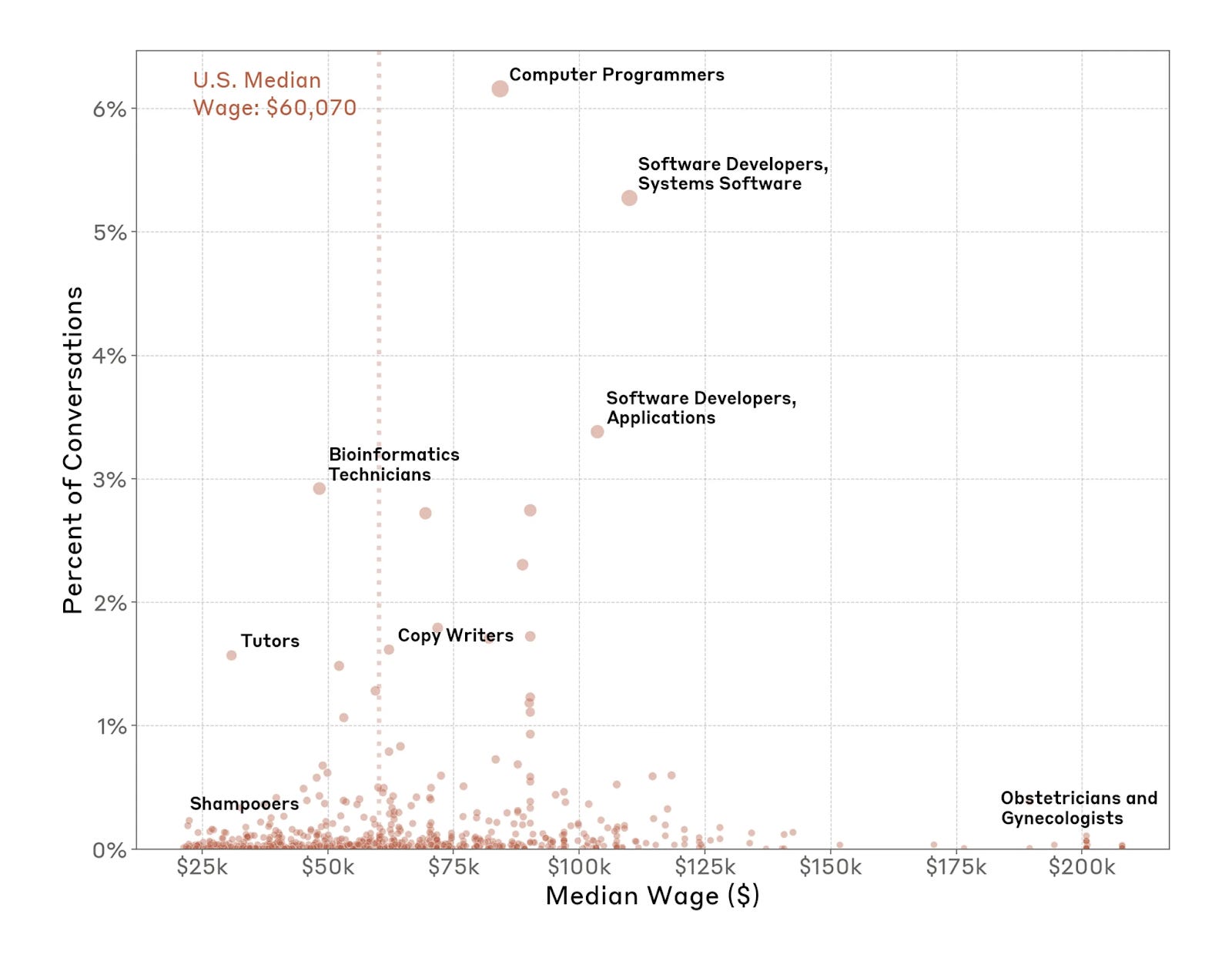
The Anthropic Economic Index has some precursory data on exposure by job. They take anonymised Claude interactions and use the models to categorise the content of these conversations. They found people are overwhelmingly using Claude for software engineering tasks.

This maps onto Michael Webb’s prospective forecast which uses semantic analysis of patents to evaluate which jobs are most exposed to AI. He found that the 88th percentile of the wage distribution was most exposed to AI, similar to Anthropic’s retrospective analysis.
The Anthropic analysis also found that 57% of queries were augmentative (“help me do this thing”) while 43% of queries were automation (“do this thing”).
The relevance of this for inequality is how exposure to AI changes the returns to talent. There are some domains where AI augmentation can ‘raise the performance floor’ by mitigating the weaknesses of the lowest skill employees but cannot meaningfully uplift the highest skill performers. This paper finds this to be true for call centre workers, supported by an LLM-based system—you can only be so good at answering the customers’ query. In some cases, using AI systems has actually decreased the performance of some high skill workers. An analysis of legal work found this. However, in some domains, and perhaps software engineering the returns to greater talent are ‘uncapped’. The absolute top performers can be many times more effective than others.
When the constraint becomes how many agents can each person manage to do more, or teams of agents, the returns to talent can be magnified in some areas. The less scarce these skills can be, the lower the wage divergence can be.
What follows cognitive automation?
Until we make progress on robotics, AI automation will be limited to cognitive labour. This can still cause the physical world to change enormously: AI systems can better organise production and can ‘deskill’ tasks that humans would otherwise do. Science is organised around principal investigators in the same way that steam-powered factories were organised around a drive belt.
Even at near-complete cognitive automation, output would remain bottlenecked by human capacity for real world tasks. Baumol’s cost disease means wages for physical tasks will be much higher than today.
To some extent, cognitive automation can help us make faster progress in robotics. A digital robotics researcher could design better experiments, create simulated environments to gather training data, and develop more efficient algorithms for training and inference. This would accelerate robotics progress, but we are still far away from robots that could do all the tasks that humans do.
We wouldn’t automate all tasks in the economy
In the second scenario, where AI and robots are capable of doing all tasks in the economy, I am unconvinced that humans would be left with nothing to do. This is for a few reasons:
First, there will be a long period where some types of context which humans have that models lack. Hayek’s essay The Use of Knowledge In Society makes the point that there are local and temporary forms of knowledge which cannot be captured by any central system.
Second, humans will retain a preference for interacting with other humans. Especially because human labour gets so expensive, goods and services made with human labour become positional goods. People will still do work which require human-to-human trust and connection.
Third, we aren’t going to give AI systems legal personhood. There is no “justice” system for AI agents and so there cannot be consequences for actions AI systems take in the world. Someone is going to have to be ultimately responsible.
Part of this is that humans want the division of responsibility. Sometimes an executive’s job is to do things that help the company, but another component of their job is so that if something goes wrong in their domain, the CEO can turn to the board and say, “Well, I hired this person who is credible and was supposed to be responsible, so it’s not my fault.”Fourth, people will create new jobs in bureaucracies. Yale University has nearly a 1:1 ratio of administrators to undergraduates. Especially as people get richer, they tend to value safety more, so there will be no limit to the amount of things we can make up for humans to do.
And finally, people can lobby governments to step in to create jobs or make it basically impossible for companies to fire people.
Based on these factors, some jobs will continue to be done by humans, and so it will be possible to retain a balance within the labour share of income. To the extent that human labour remains a complement to capital, because of the factors mentioned above, then labour will retain an equivalent share of income. The idea that ‘capital’ will dominate labour’s share of income (i.e. capital will take all of the gains) depends on the idea that AI systems and robots will be perfect substitutes for humans. Nowhere do humans retain a comparative advantage.
One way to think about this is to imagine, in 1800, if you saw all the mechanisation coming, surely you would assume that ‘capital’ becomes an enormous fraction of the economy, but it didn’t and things remained in equilibrium because wages rose too. Everything balances out, just at much greater equilibriums, so long as labour remains a complement to capital (or the rules arbitrarily enforce this should be the case).
I expect this second scenario will take a long time to come to pass, much longer than most people in AI, for reasons discussed here. Overall, I think the picture is optimistic. It ultimately hinges on your view of human nature — how much do we value the humanity of other people in our transactions? When people get richer, they buy fairtrade and other “ethical” products. People do care about the provenance of positional goods, and they do care to watch other humans race cars around tracks, based on arcane rules, to watch sports and chess. I expect, and hope, this remains in the future.
If we can accelerate educational attainment to give as many people the skills for AI as possible, we should avoid a future with greater inequality.