
Getting AI datacentres in the UK
Why the UK needs to create Special Compute Zones; and how to do it.



Here is some context on the current situation:
Since 2012, the computational power used to train the largest AI models has grown 100 million-fold. This has become enormously energy intensive: the most recent model from Meta used an estimated 27 megawatts of power capacity, which is approximately the same power required for 88,000 UK households, approximately the same as York. If trends in computational power scale-up continue, by 2030, training the largest model would use 2.15 times the UK’s entire energy generation capacity.
The AI developers are power constrained: Microsoft has committed to a 20-year power purchase agreement to reopen Three Mile Island; Google and Amazon have entered partnerships with energy developers to construct new Small Modular Reactors; and Elon Musk’s x.ai has converted a factory in Memphis into a datacentre, and put natural gas generators outside. SemiAnalysis, a leading third party research group, estimates that AI datacentre power demand will grow by 40 gigawatts globally in the next two years, roughly 200 times the average power demand of Liverpool.
We investigated the feasibility of low-carbon power sources to power AI datacentres in the UK: either a combination of wind, solar, grid batteries, and natural gas backup; or using nuclear power. Our modelling found that the cost-minimising allocation of renewables would require over 200km2 of contiguous land area per gigawatt, which would need to be next to an LNG import terminal. Furthermore, this would have 40% higher carbon emissions, and lead to 27 times more ‘expected deaths’ than using nuclear power, based on historical patterns.
However, as things stand, no developer would choose to build an AI datacentre in the UK. The UK’s nuclear construction costs are 4.5 times higher than South Korea, and building reactors takes twice as long. Approving a new power plant has taken 6 and 12 years in the last two instances, while approving a reactor with the same basic design in France took just 3 years. If a datacentre operator wanted to connect to the grid instead of building new power, it would take up to 15 years to get a grid connection, and the industrial electricity prices are four times higher than in the US and 45% higher than in France.
Despite these facts, the UK can make a series of reforms and, in just a few weeks of swift action, the UK can become the best place in the world to build AI datacentres and the nuclear power to support them. Special Compute Zones would create an alternative planning and regulatory approval process for nuclear power, AI datacentres, and the transmission and networking infrastructure to support them. If these reforms allowed UK projects to close the cost gap with South Korea by two thirds, nuclear power would become 37% cheaper than an equivalent blend of renewable power for datacentres. With high levels of speed and certainty during the approval process, the UK has the opportunity to catch the wave of AI infrastructure development.
Navigating the report
The Overview can be read as a standalone. For more details…
‘AI progress is very quick’, explains what investors are buying into.
‘How AI became computationally intensive’, offers a brief and simple technical introduction to why AI systems use so much computational power.
‘Further progress and deployment of AI systems will use 10’s to 100’s of gigawatts’ shows the historical trends in computational intensity and what forward-looking estimates suggest for the energy-intensity of AI.
‘The UK would power AI datacentres using nuclear power, not wind and solar’ evaluates the suitability of low-carbon energy sources.
‘Going without AI datacentres would be a mistake’ sets out the case for why the UK needs to have AI datacentres, and not depend on international markets.
‘Nuclear power is slow and expensive to build, but it could be cheaper and faster’, is a diagnosis of why UK nuclear construction costs are so high, and how this might be remedied.
‘The UK should create Special Compute Zones’, suggests the implementation details for making the UK the best place in the world to build AI datacentres.
We would like to extend thanks to John Myers, Robert Boswall, Nathaniel Read, Freddie Poser, Ben Southwood, Mustafa Latif-Aramesh, and Samuel Hughes; for their feedback and comments on this work.
We would also like to acknowledge the work of Britain Remade, in particular Sam Dumitriu, whose high-quality analysis of nuclear power and infrastructure costs was instrumental in this proposal.
Overview
Some kinds of growth are difficult to achieve. One way people create economic growth is by making a new discovery in a lab, doing the engineering work to turn this discovery into a product, and then running a business to distribute the product to the world. The academic literature suggests this kind of growth is getting harder over time—it requires adding ever more researchers to maintain a consistent rate of breakthroughs. This is what economists call ‘frontier’ growth—this requires doing something nobody has done before. On the other hand, some other kinds of growth can be comparatively simple: an investor might come along, looking to repeat a technique proven to work elsewhere, and they'd like to build a factory of some sort to replicate it. Enabling this kind of ‘catch-up’ growth is a choice.
The UK has been without growth for many years. Since 2007, per capita GDP has grown by just 0.35% per year and total factor productivity growth has been flat.
Sometimes, a new type of frontier growth will emerge: a combination of scientific breakthroughs will lead to the creation of a new ‘general purpose technology’. There have been three in modern history: the steam engine, electricity, and information technology (computers). These technologies will spread through many industries, and become a platform for the development of further technologies. Each general-purpose technology took decades to reach mass adoption, but each provided a huge opportunity for economic growth. The Industrial Revolutions were organised around a general-purpose technology: the First Industrial Revolution was steam power, the Second was electrification, and the Third was digitalisation.
Such a breakthrough is happening today, in artificial intelligence (AI).
AI is poised to do for cognitive labour what the steam engine did for physical labour
One way to think about the impact of AI is using the steam engine as an analogy. In the First Industrial Revolution, there was a clear input and output relationship—pour in coal, and get out rotational power in a crankshaft, which could be used for all sorts of downstream tasks (trains, factories, more coal mining). What makes this so powerful is that it is dependable—every time one adds coal, they know what will happen; it is general—the rotational motion can be applied to any of these use cases; and it is scalable—so long as one can design a bigger steam engine, there is no limit to the amount of coal an engine can usefully convert into power.
A latent resource we have today—just like the British in the second half of the eighteenth century had a lot of latent energy in surface coal—is computational power in computer chips. Over the last 60 years, the number of transistors (think: computational power units) on a chip has doubled every two years, giving us an enormous supply of computational power. One intuition for what the field of AI is trying to answer is, “How can we exchange this computational power for useful information processing capabilities?”.1 This requires finding the system of pipes and valves—or in this case, the combination of architectures, algorithms, data, and the training procedure—to make the input-output relationship work.
Over the past 12 years, AI researchers have found the broad combination of variables which allow them to add more input. Today’s state-of-the-art systems score very highly on capability benchmarks. They outperform PhD-level experts on a benchmark testing for scientific expertise; score in the 99th percentile on the US law school admissions test (LSAT)2; and are capable of winning a silver medal on the International Mathematics Olympiad exam (for the best sixth-form age students in the world). These capabilities have translated into economically useful performance: on software engineering tasks, in customer support, and in materials discovery.
AI systems will support economic growth in three main ways:
AI will let us automate existing information processing tasks
As the cost of information processing declines to zero, we will use this new abundance to create new products and services.
AI can help to accelerate research and development to drive frontier growth.
What is important to understand about the input-output relationship of AI systems is that there are extremely dependable improvements on the specific task they have been trained to do. However, general purpose AI systems have been trained primarily to predict the next word in a sequence, and so it is genuinely uncertain whether improvements at text prediction will continue to transfer to useful capabilities in the system; and by extension, whether these will transfer to economically useful tasks. OpenAI’s GPT-3, the first system which most people had experience with through ChatGPT, had useful capabilities—it was good at writing sonnets—but it was GPT-4 that could begin to do coding. So far these improvements have continued to transfer, which explains the impressive capabilities and economic interest in AI systems.
The computational and energy-intensity of AI is only getting greater
Because of this uncertain exchange rate between compute and ‘capabilities’ broadly, AI developers want to continue increasing the computational inputs to create and run these systems, and they want to sell the current capabilities as broadly as possible. The challenge is that increasing computational power is enormously energy-intensive. AI systems use specialised chips, predominantly the Graphical Processing Unit (GPU) designed by NVIDIA. Each state-of-the art GPU uses an enormous amount of power: if used continuously, it will consume 44% more power than an average UK resident.3 To support this energy and computationally intensive process, AI chips are hosed in datacentres. These are specialised warehouses which are optimised to manage the cooling and energy requirements of the chips. From the outside, these are ordinary buildings on an industrial park.
The most recent AI system from Meta (called Llama 3.1) was trained using 16,000 active GPUs in a single datacentre, which is estimated to have required 27 megawatts (MW) of installed power capacity. This is roughly equivalent to 88,000 UK households.4 One useful intuition is that a single datacentre will use as much power as a small city.
As developers are betting on the input-output relationship holding, computational power is being scaled up at breakneck speed—the amount of computational power used in training the AI systems has grown 5 times over per year since 2017. Were the current trend to hold until 2030, training the largest AI system would require approximately 2.15 times the UK’s entire electricity generation.5 Meta’s release of Llama 3.1 in July 2024 might begin to look very small indeed! Running the systems, too, is set to become more energy intensive: new methods have been developed to input additional computational power whilst the model runs, to enhance capabilities further. Jensen Huang, the CEO of NVIDIA, expects this to grow by “a billion times”. More details on these trends are covered in the main body.
There is a wave of capital investment to build 10s to 100s of gigawatts of datacentres and power for the next decade
To continue increasing the input of computational power, the AI developers and the ‘cloud providers’ who sell them datacentre capacity, are growing their operations as quickly as possible. SemiAnalysis estimates the power demand from AI datacentres globally will grow 40 gigawatts (GW) by 2026, and in the US alone, by 47.8 GW for 2028, from just 8.5GW in 2024. To put this into perspective, one GW of continuous power demand is five times the average power demand of Liverpool.6The addition of AI datacentres globally in the next two years will use roughly 200 times the power demand of Liverpool.
This enormous surge in demand is constrained by energy generation. There is simply not enough power. As a result, AI developers are signing long-term power purchase agreements to bring nuclear power plants back online, and are signing development agreements with developers of ‘Small Modular Reactors’ (SMRs). Perhaps most dramatically, Elon Musk’s company, x.ai, has even converted a factory in Memphis into a datacentre for 100,000 GPUs in just 19 days, and is using natural gas generators outside to make up the power it needs.
No developer would build an AI datacentre in the UK by choice
As things stand, the coming wave of capital investment will bypass the UK. No AI developer or cloud provider would choose to build an AI datacentre with new power in the UK:
Planning permission for the datacentre would take too long. Until recently, datacentres went through Local Planning Authorities under the Town and Country Planning Act 1947, but the Labour Government is going to make them ‘Nationally Significant Infrastructure Projects’ which require a Development Consent Order from the Secretary of State, with the aim of accelerating the process. However, the average period of consideration for a Development Consent Order in 2020 was 22 months, and since the last election, ministers have delayed 40% of decisions on Development Consent Order decisions, and so it is likely there would be further delays.
If a datacentre operator wanted to use grid power, it would take up to 15 years to get a grid connection, and even then the UK’s industrial electricity prices are four times higher than the US and 45% higher than France.
If the datacentre operator wanted to procure their own nuclear power, it would take 6 to 12 years to get approval, and once they have approval, construction would take 12 to 15 years.
The current pace of planning, regulatory approval, and construction is too slow to keep pace with the wave of investment.
If the UK wants AI datacentres, nuclear power would be the safest, cleanest, least land-intensive, and could also be the cheapest.
We investigated which energy generation method would be most suitable to power AI datacentres. We compared the feasibility of nuclear power, or a blend of wind, solar, grid battery storage, and natural gas backups.
We calculated the cost-minimising way to blend renewables with batteries and gas, to provide the permanent power supply datacentres require, and found that per gigawatt of firm power, it would require 8 GW of installed solar power, 0.37 GW of wind power, 12 GWh of battery backup, complete gas backup, and LNG import capacity for 451 million cubic metres of gas. This would become infeasible on multiple grounds:
Land intensity—8 GW of solar panels and 0.37 GW of wind turbines would require 160km2 and 41km2 respectively. (As a point of reference, Cardiff is 140km2 and Reading is 40km2.7) This scales very poorly. Some datacentre campuses are much larger than one gigawatt, for example, to power Microsoft and OpenAI’s 5GW datacentre campus in Virginia it would require over 1000km2 of contiguous land.
Emissions—because of the intermittency of wind and solar, natural gas would generate 28% of the power, which would produce 40% more carbon than equivalent nuclear capacity.
Safety—the air pollution from natural gas emissions would be many times more dangerous than the risk of a nuclear accident, resulting in 27 times as many expected deaths.
Limited proximity to LNG import capacity. The UK has three LNG import terminals, one in Kent and two in South Wales. The natural gas generation terminal would need to be some distance from population centres to reduce air pollution, but also close enough to the import terminal that gas pipelines are not necessary. It is either necessary to find ways to build these generation facilities in Kent or South Wales while being contiguous with the solar and wind farms, or it might be necessary to build a new LNG import terminal, but neither approach scales well, and the latter would add substantially to costs.
Cost—we calculate a levelised cost of blending wind, solar, batteries, and natural gas at £106/MWh, which is lower than the current CfD price for Hinkley Point C (£143/MWh8), though there are large opportunities for cost savings with nuclear power—South Korea builds at roughly 25% of the cost of the UK—and so if two thirds of the cost gap with South Korea could be bridged, the cost would be 37% cheaper than renewables. (In Texas, renewable energy at the same emissions intensity for £74/MWh.)
Building nuclear power plants in the UK has been slow and expensive, but it doesn’t have to be. Some relevant facts:
Two thirds of the cost of Hinkley Point C was interest—if you can bring down the cost of borrowing, this can cut the final cost of electricity in half.
South Korea builds 8 to 12 copies of the same reactor design. This means they benefit from learning, both technically, and in terms of the regulation, and they have a consistent supply chain of components and of people with the skills to build a reactor. On the contrary, Hinkley Point C was a one-of-a-kind reactor which had 7,000 design changes from the basic design already used in France and Finland, and was the first nuclear power built in the UK in 21 years.
Responsibility for nuclear power plant approval has been diffused between many actors who can say ‘no’, or who might add incremental delays and cost increases to new nuclear power plant construction, which amounts to a de facto ‘no’; but there is no positive force in the system who pushes for power plants to be built.
Small Modular Reactors (SMRs) provide a big opportunity for the UK. Because most assembly happens in a factory, large productivity gains during manufacturing are possible, and on-site construction can take just months. Furthermore, SMRs are especially suited to AI datacentres because there can be a fleet powering a datacentre campus, and so when there is an outage, there is a diversified power supply.
Making UK nuclear power competitive is the only way the UK would attract AI datacentres: if a datacentre provider wanted to use a blend of renewables, they would be likely to be much better off in West Texas.
It is possible to bring the costs down—there is a lot of low-hanging fruit to be picked!
The UK needs AI datacentres for economic security, growth in former industrial areas, and to seize the opportunity of future frontier growth
At this point, a sceptic might ask whether it is worth trying at all. In general purpose technology revolutions, most of the gains come from adopting the new technology, and seem unlikely to accrue to those who host AI datacentres. Perhaps this wave of investment is going to happen, but can’t the UK just focus on ‘high-value’ activities, like integrating AI systems and building AI applications.
We don’t think so—first and foremost, there’s no scarce resource being used up by permitting this growth, all the capital is from private investors, and the UK needs the growth. Most importantly, however, the UK needs the critical inputs for its future economic engine, the old economic dogma—that it is possible to sit atop the value chain and focus only on the ‘high value’ activities—is incorrect. This causes the hollowing out of industries, and neglects the valuable ‘learning-by-doing’ that allows us to make future growth. The UK without datacentres will lack the critical inputs for its future economic engine.
The Chancellor Rachel Reeves has frequently promoted a new doctrine of ‘securonomics’, of which the core tenets are prioritising economic security in an ‘age of uncertainty’, not depending on a narrow set of industries from London and the South East to drive growth for the whole country, and seizing the opportunities of a rapidly changing world.
Hosting AI datacentres in the UK is central to all three tenets.
First, as AI systems become increasingly integrated into the economy, especially into the UK’s professional services export businesses, a large fraction of the UK’s capital stock will be created in, stored in, or run in AI datacentres. The UK will want these AI datacentres to be here, rather than overseas and connected through an undersea cable, to ensure it can protect these assets. Furthermore, as adoption is critical to capturing the gains, the UK needs to ensure it has computational power capacity it needs. As demand for computational power rises globally, it could be the case that UK businesses are unable to access this. The Microsoft CFO said on an earnings call two weeks ago that revenue growth in their cloud business was 33% but, “[d]emand continues to be higher than our available capacity.”
Second, the Government’s AI Sector Study shows that 75% of UK AI companies are based in London, the South East, or East of England. This is to be expected: AI application developers will agglomerate around London because it has the best venture capital ecosystem and AI talent density outside San Francisco. However, as the Chancellor has said, there has been, “[a] misconceived view held that a few dynamic cities and a few successful industries are all a nation needs to thrive…[t]he result was a paucity of ambition for too many places, the hollowing out of our industrial strength and a tragic waste of human potential across vast swathes our country.” It is now very rarely the case that growth can be so readily directed towards areas with a strong industrial past, but that is the opportunity of AI datacentres—it is possible to bring the Fourth Industrial Revolution to the rest of the UK as well, if the rules allow it.
Finally, given that AI systems are likely to play a critical role in research and development. The UK has world-leading science and technology clusters, whose work is likely to be transformed by AI systems. Running AI systems that support research and development—AI for science—will be critical to any frontier growth in the UK for decades to come, and it is not possible to depend upon international datacentre markets to supply the services which are so central to our future prosperity. They would need to be here.
The UK has already missed an opportunity for frontier growth—UK scientists like Geoffrey Hinton and Demis Hassabis were at the forefront of the AI revolution, which is now being commercialised by a small handful of US firms. The UK is about to pass up the opportunity for the easiest kind of growth—someone wants to build AI datacentres and power to support it. The money wants to flow but the revealed preference of our current regulatory and planning system is that it should not.
The UK can become the world’s best place to build an AI datacentre and the power to support it
This can all be fixed in as little as a few weeks. To do this, we propose creating ‘Special Compute Zones’—which provide an alternative planning and regulatory approval process that fixes the issues with the current approach. It would provide the certainty, speed, and hence, the opportunity to be cheap, which is currently lacking.
Developers could receive a single point of signoff for the power, datacentre, and transmission and networking infrastructure they require. Within the Zones, there would be ‘deemed consent’—meaning the default answer to construction is ‘yes’—and permission to construct would have to be challenged within three months of an application. Ordinarily, a planning decision will weigh the relative merits of each project; but within a ‘Special Compute Zone’, it would be decided that by creating a zone, this cost-benefit is pre-considered, and therefore approval would depend on a ‘condition-based approach’—if a developer can show that the project meets particular standards, it goes ahead. There is precedent for this kind of approach in the EU and Spain, where ‘Renewable Acceleration Areas’ use condition-based approaches. We present more details on implementation below.
Missing this wave of capital investment is like missing the railways
Between 1841 and 1850, private investors ploughed a cumulative 40% of UK GDP into building the railways—imagine if instead our planning and regulatory regime had prevented this investment and the UK’s rapid economic growth! The UK continues to collect the dividend from this period of growth today, 170 years on.
Sometimes growth is difficult to come by, but in this case, growth is a choice: all we need to do is unhobble ourselves.
1. AI progress is very quick
The goal of AI research is generally intelligent systems
To begin, it is useful to clarify what AI research is aiming at, as people use many different terms. These include Artificial General Intelligence (AGI), Artificial Superintelligence (ASI), human-level AI, powerful AI, and transformative AI. The terms can be somewhat misleading—does ‘human-level AI’ refer to AI systems which perform at the level of the average human, or the smartest human? Furthermore, the development of AI systems is ‘unbalanced’, in some ways current systems already surpass the smartest humans, but in other ways they fall far short.
Debates over these definitions can distract from focusing on the most important thing: very capable systems might be created before we have clarified whether ‘true’ AGI requires, say, emotional intelligence. To avoid these pitfalls, three terms can be useful:
A Drop-In Remote Worker refers to an AI system that can interact with a computer, pursue tasks for weeks-equivalent of human time, at the level of a graduate remote worker.
An Expert Scientist refers to an AI system that can perform scientific research, at the level of the world's best scientists across a variety of scientific domains.9
A Superintelligence refers to an AI system that exceeds human intellectual capabilities across all relevant cognitive skills.10
The explicit goal of the AI research labs is to create a software program that is an Expert Scientist. When DeepMind was founded in 2010, their mission was: “To solve intelligence, and then use that to solve everything else.”
AI researchers are making progress towards this goal
Whether expert scientists are possible in the current technical paradigm is genuinely uncertain, but current state-of-the-art systems can do a lot:
Coding assistance. State-of-the-art AI systems are very effective at giving assistance to professional software engineers. This research found that software engineers were 55.8% faster at completing a software-engineering task with assistance from an AI system, and the former head of self-driving at Tesla, Andrej Kaparthy, wrote that he, “basically can't imagine going back to ‘unassisted’ coding at this point”.
Scientific capabilities. State-of-the-art systems outperform experts with relevant PhDs on GPQA diamond, an evaluation which tests expertise in physics, chemistry, and biology.
Mathematical abilities. DeepMind’s AlphaProof was trained to solve problems from the International Mathematical Olympiad, and achieved ‘silver medalist’ performance—roughly equivalent to scoring in the top 100 sixth form mathematicians in the world. OpenAI’s ‘o1’ was not trained specifically to perform well at maths questions, but scored 80% on a US Mathematics Olympiad qualification exam, which is equivalent performance to the top 500 high school students in the USA.
Agentic improvements. AI systems can complete small software engineering projects. SWE-Bench Verified is a benchmark which measures the ability of AI systems to perform real world software engineering tasks: OpenAI’s GPT-3.5, the state-of-the-art model in 2022 performed poorly, only able to complete 0.4% of the tasks. As of November 2024, Anthropic’s Claude 3.5 Sonnet was able to successfully complete 53% of tasks. For another example, OpenAI’s o1 successfully completed 100% of the problems posed to interviewees for software engineering positions at OpenAI.
Where AI progress goes from here is very uncertain
While the historic trajectory of AI progress is clearly very steep, it is difficult to know whether this implies that capability improvements will continue, and exactly what this might look like. Most importantly, we do not have a large suite of benchmarks for assessing the capabilities of the most advanced AI systems. Because the AI systems have improved so quickly, our evaluations ‘saturate’, meaning that all systems score indistinguishably high scores. For example, MMLU and MATH were benchmarks released in 2020 and 2021, and specifically designed to resist this kind of saturation. GPT-2 scored 32.4% on MMLU and 6.9% on MATH at their release, but in just three years, they approached saturation: GPT-4 scored 86% and 84% for MMLU and MATH respectively. The chart below shows examples of saturation across benchmarks
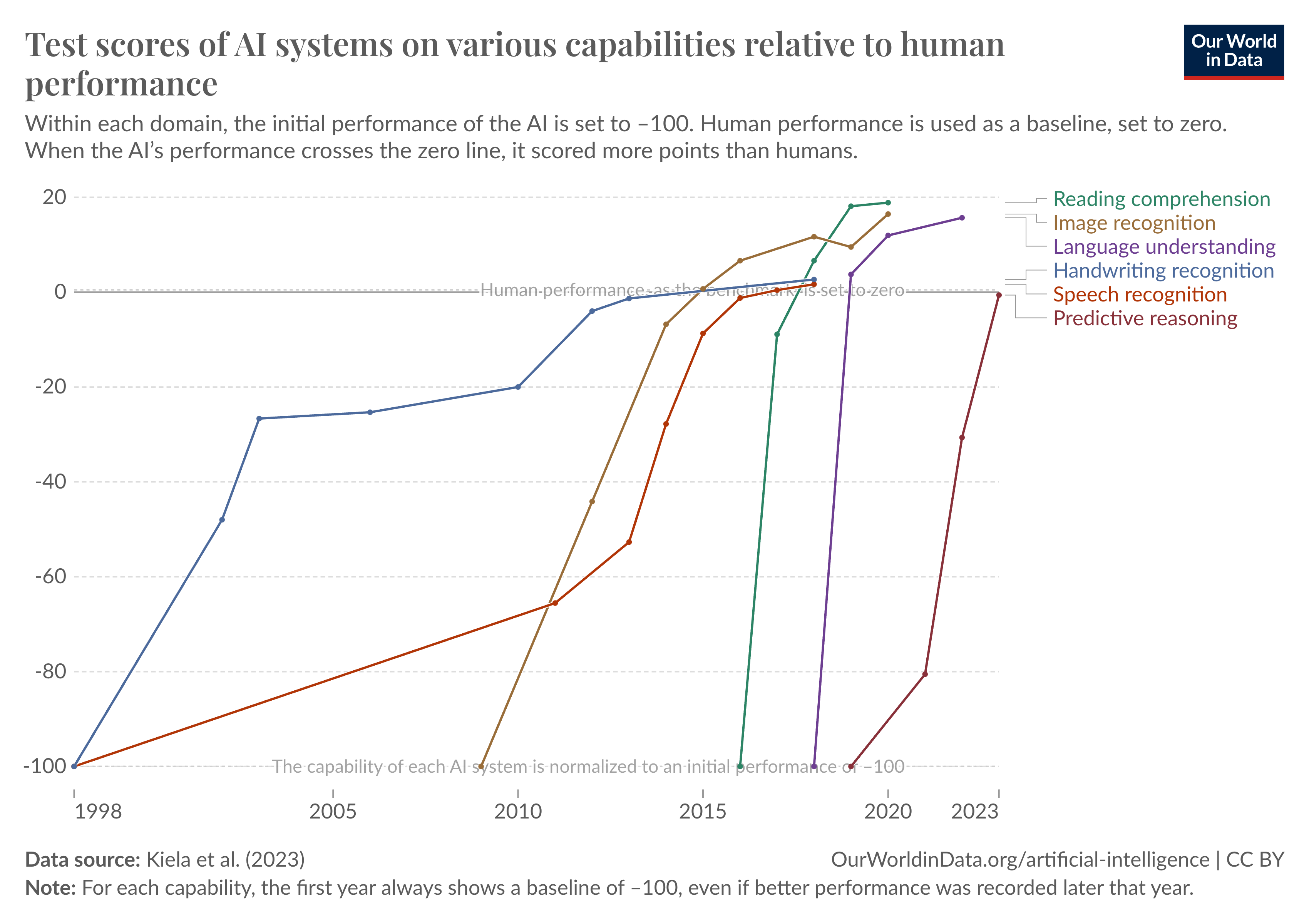
Some of the best benchmarks that we have for scientific capabilities—GPQA diamond and LAB-bench—require the models to answer multiple-choice questions about the subject matter. These questions can be thoughtfully designed, but the conclusions from these tests are limited. They imply the systems were very good at answering a narrow set of scientific questions, it doesn’t imply very much about whether the models can do the work. For what it is worth, the AI systems clearly aren’t just multiple choice machines—systems seem to be able to solve problems from the famously difficult Classical Electrodynamics which can require days worth of effort from graduate-level physicists.
One approach to understanding the scientific capabilities of AI systems is to decompose the process of doing research into discrete steps, and evaluate each step piecemeal. For example, this paper tested hypothesis generation, and found, "LLM-generated ideas are judged as more novel (p < 0.05) than human expert ideas while being judged slightly weaker on feasibility”. The AI developers and the UK and US Safety Institutes are likely to maintain more comprehensive private taxonomies to track progress across the research pipeline, though there are strong incentives for these organisations not to release these.
Aside from benchmarks, it can be difficult to interpret progress clearly, because the people on the very frontier, who can see best where progress is headed, have been very heavily selected for conviction in the current technical paradigm. Sometimes, these researchers are modelled as capitalists, ‘hyping’ the potential future capabilities to fundraise or make a project. This is an incomplete picture—no doubt there are people within AI labs who are ‘selling’ the future, but there are also many researchers who very sincerely think that AI systems will have transformative capabilities. For example, the Chief AI Scientist at Anthropic, Jared Kaplan, who is also a Professor of Theoretical Physics at Johns Hopkins, said in a talk at CERN: “I think in certain respects AI systems are approaching human level performance. I think there are some challenges for continuing this progress but I think there aren’t any really compelling blockers for AI doing things like helping to automate science.” Likewise, John Schulman, the cofounder and former head of ‘post-training’ at OpenAI, anticipates that AI systems will match top AI researchers within 5 years, and Demis Hassabis, the CEO of Google DeepMind, believes, “we are in shooting distance of curing all diseases”. These claims should be treated with a healthy mixture of scepticism and seriousness, and they should not be dismissed out of hand.
This picture is made evermore difficult by the distortion of academia. Because AI developers pay salaries 10 times or more what can be earned in academia, there has been an enormous movement out of universities into OpenAI, Google DeepMind, and Anthropic. Those who are left behind are strongly selected from scepticism of the current technical paradigm.
The essential takeaway is that there have been very steep improvements in AI capabilities thus far, and as we will discuss in the next section, there are compelling reasons to believe this will continue. But exactly how this evolves, and where it might end is very uncertain. However, the most optimistic case—which is sincerely held by a number of people building on the frontier—is that this could usher in a period of explosive economic growth (~20% GDP growth or more).12 Though it is unlikely, it is within the realm of possibility.
2. How AI became computationally intensive
Some breakthrough technologies unlock our ability to exchange a latent resource for useful outputs. Steam engines are like this—pour the coal in, and the steam engine reliably converts the energy into the rotation of a crankshaft. This has all kinds of downstream uses: moving a train carriage, driving a pulley in a factory, or pumping water. Likewise, in the Haber-Bosch process, pour in hydrogen and nitrogen, and receive ammonia, which can be used as fertiliser. What makes these processes so powerful is their scalability: to move more goods before the steam engine, it would require adding more packhorses to carry goods along a turnpike road; before the Haber-Bosch process, growing more crops meant sending more boats to the Chincha Islands to harvest guano. With technology, there is dependable leverage—it is possible to continuously add more latent resources and receive back useful outputs.
Computational power is the unit of information processing, in brains and in computers. It would be incredibly useful if we could develop a technology which allowed us to pour in computational power and exchange this for useful informational processing capabilities. ‘Ordinary’ computing does a version of this; but it is fragile and limited. Ordinary computers can only do processing tasks which have been specified by a program in advance, whereas AI systems have the capacity to learn. This is one intuition for what AI research is doing: it is finding reliable and scalable mechanisms—just like the steam engine or the Haber-Bosch reactor—that allows us to exchange processing power for flexible and adaptive intelligence.
This is unintuitive. Prima facie, AI research should be about having deep insights into the nature of intelligence, and designing machines that reflect these insights. Computer scientist Rich Sutton has called this realisation, ‘The Bitter Lesson’—what has driven AI progress is not the profound theories of researchers, but general strategies which allow AI systems to leverage greater amounts of computational power. In earlier approaches to AI, researchers would ‘hand-code’ how they thought an AI system ought to learn, for example, what features of an image to recognise in order to classify the picture; but neural networks, the foundation of modern AI, allows the system to learn for itself what features are salient, through a training process.
Increasing the amount of computational power during training
The neural network is like a little computer which can be programmed by adjusting a series of dials. The aim of a neural network is to predict an output given a set of inputs. The iterative process of tuning these dials to improve the prediction is called ‘training’. The people creating the network supervise the training process by showing the data and the answers, but crucially, it doesn’t involve telling the network how it ought to process and understand the image. In other words, our process of trial and improvement tweaking of dials is essentially letting the little computer, by itself, search for the best way it can be programmed to achieve its goal, unlike ordinary computers which need a human to figure out a program first and then somehow communicate it to the computer. Dario Amodei described the training process in this way:
“You [the AI researcher] get the obstacles out of their way. You give them good data, you give them enough space to operate in, you don't do something stupid like condition them badly numerically [i.e. tweak the dials poorly], and they want to learn. They'll do it.”
What your neural network will end up learning depends on the goal you give them to pursue, and in what you ask the network to predict. There’s two ways it is possible to do this:
Directly optimise for a specific capability.
Optimise for a related goal, and hope that important capabilities emerge downstream.
Large language models, the basis of recent progress in AI, take the second approach. A language model is optimised to predict the next word13 in a sequence, based on the words that have come before. Google DeepMind’s Gemini 1.5 model is able to take in nearly one million words of input, to give the most subtle and accurate prediction of the next word of output. This isn’t an inherently valuable task in the way that a neural network which is trained to predict whether a dot on the screen is a tumour or a harmless cyst is inherently useful.
While predicting the next word isn’t inherently useful, pursuing this goal is still enormously powerful. Text has a very rich structure, meaning the words aren’t randomly assorted: whoever wrote them chose their order to convey an idea. If a neural network can understand that structure—say, by parsing all of human knowledge in the training process—the network has a representation of how everything fits together. Researchers would call this a ‘world model’.
Prediction is a meaningful task—if the network can take most of a book as input, and predict the end without having seen the book before, there is some sense in which it understands the content.14
The measure of how far these predictions are from reality is known as the ‘training loss’. There is an extremely predictable relationship between the model’s size, the amount of training data it uses, the amount of computational power (compute) it is trained on; and the model’s loss. As the models get bigger, and are trained on more data, using more compute; its loss declines. In other words, its predictions get better. Amodei has noted the declines are, “sometimes predictable even to several significant figures which you don't see outside of physics.”
What is much less predictable is whether these declines in training loss translate into useful capabilities. It has been particularly surprising how well improvements on next token prediction have converted into useful capabilities so far. In expectation of these capabilities, AI developers have scaled their models dramatically: Google DeepMind’s Gemini 1.5, released in December 2023, was trained using 6.7 million times the amount of compute used to train a state-of-the-art large language model in June 2017. To put this in broader perspective, since 2012 the amount of computation power used to train the largest models has grown by 100 million-fold.
Using more compute while the model is running
Thus far, we have only described the opportunity to pour in additional compute during the training process to receive useful outputs. It is also desirable to pour in additional compute while the model is being used; technically called ‘inference’. A paradigm example of an AI system to take advantage of ‘inference-time compute’ was DeepMind’s AlphaGo. AlphaGo was trained to play the board game Go, or, to be specific, it was trained to find the next move from a given board state which maximised win probability. One way the system might have solved this problem is to imitate the moves of a human expert. Indeed, this was the initial approach to training. But a more advanced way of learning would be for the model to play against itself predicting what could happen in future moves and learn from that guess. This kind of planning could also be used when the model was competing. When DeepMind’s system was allowed to use this additional capability before choosing a move, performance jumped from 1500 ELO to 3000 ELO.
AlphaGo was able to exchange compute at inference-time for a jump in capabilities because the game of Go is well suited to running a form of tree search. It has a very clear goal (to win the game) and it has a reasonably constrained search space (the potential moves on the Go board). Determining the best next step is relatively straightforward.
By contrast, ‘language space’ isn’t like this. There are many prompts which do not have a formally ‘correct’ response—determining what is ‘better’ is much more subjective. Also, the ‘space’ of potential directions in language is much larger than the potential next moves on a go board, especially as the responses get much longer. It would be very difficult for a tree search procedure for language to know what direction to search in. Because of this, when ChatGPT was released in November 2022, it had been trained on 500 billion tokens (think: words) but it could only use 4,096 tokens to respond to each prompt. It couldn’t use more compute while it was running to generate better answers; it was hobbled.
This changed in September 2024. OpenAI released ‘o1’, a new series of models which generate ‘Chains of Thought’ before responding to a prompt. Chains of thought allow the model to use additional processing in response to more difficult questions. In the o1 release blog post, OpenAI showed a graph that demonstrates how as the compute budget is expanded, its performance on a qualification test for the US Maths Olympiad improves.

The important takeaway from this section is that AI developers are constantly improving their understanding of how using more computational power can increase the useful capabilities of the models. Granted, the current methods for applying additional compute might stop having returns, but it is likely that the future methods we find will continue to follow this pattern.
In the current world, intelligence is scarce and special—just as fertiliser or mechanical power was before the steam engine. It is weird to say, but creating more intelligence today is laborious: it occurs only in humans who take decades to mature and require lots of education. In the not too distant future, intelligence equal to, or beyond human-level, will be constrained only by our ability to pour in computer chips and electricity.
3. Further progress and deployment of AI systems will use 10’s to 100’s of gigawatts
Let us begin with historical trends. Since 2012, the amount of computational power used to train the largest models has increased 100 million-fold: how have we done this? There are beneficial tailwinds: the computational power of the state-of-the-art AI chip has doubled every 2.3 years, as shown in the chart below; and the energy efficiency of hardware has doubled every 3 years.15

However, the increase in training compute exceeds the rate of hardware improvements: since 2010, training compute has doubled every six months! Language models have moved faster still: doubling happens roughly every five months, shown in the graph below.

While using a computer at home is not at all energy-intensive, the kind of computation that AI systems are doing is very energy-demanding. A state-of-the-art chip, the H100 Graphical Processing Unit (GPU) made by NVIDIA, has an annual power draw 44% higher than the average UK resident!18 This is set to increase, in the next generation chip (the B200) to 150% more power than the average UK resident. The exact amount of power that Google DeepMind, Anthropic, and OpenAI use to train their systems is kept secret, for competitive reasons, but Meta published a report with their latest model release in July 2024, which noted that training their largest model used 16,000 active GPUs. EpochAI, a third-party research organisation, estimates this required 27 megawatts (MW) of installed electricity capacity.19 This is approximately the power supply required for 88,000 UK households, which more than the number of households in York.20
One useful intuition is that each AI chip has the power demand of a person, or maybe soon a household, and each AI datacentre has the power demand of a small city. The large datacentre campuses will be similar to the largest cities. Of course, it is quite remarkable how much power it takes to train the current AI systems, but the steep trendlines point towards this amount of computational power and energy becoming quite small, quite quickly!
What is the future of AI datacentre and energy demand?
A report by a former OpenAI employee, Leopold Aschenbrenner, extrapolated the current trendlines in computational power increases, and noted that current growth rates imply:
The largest model in 2026 will be trained on the equivalent computational power of one million of today’s state-of-the-art GPUs and require 1 gigawatt (GW) of power. (Of course, hardware improvements mean it will be a smaller number of more intensive chips, so hereafter we’ll use the unit H100-equivalent for comparison.)
In 2028, the largest model will use 10 million H100-equivalents of computational power, and 10GW of electricity.
In 2030, this will jump to 100 million H100-equivalents and 100 GW of electricity.
This is daunting. The 16,000 H100s which Meta used to train their most recent model, which required the same power as York, looks microscopic in comparison to the figures for the simple extrapolations for the end of the decade. Were this trendline to hold, and the length of training runs reaches optimum, the single largest model in 2030 would require 2.15 times more power than the UK’s entire electricity generation in 2021.21 Of course, this is not a prediction, merely an observation of what continuing straight lines would imply.
Thus far, we have only described trends in training compute, not in the inference of systems (i.e. when the models are being run). If the inference-time compute paradigm which OpenAI have developed using chains-of-thought can be extended further, the computational intensity of inference will rise sharply. This will be compounded by increased frequency of model inference. As AI systems become more integrated into the economy, inference will become the dominant form of AI computing by far. Jensen Huang, the CEO of NVIDIA, expects the amount of inference to go up ‘by a billion times’ (and given the 100 million times increase in training compute in the last decade, we take this estimate seriously!)
SemiAnalysis published an estimate in March 2024 that US ‘AI Data Centre Critical IT Power’ will rise to 56.3 GW in 2028, from 8.5 GW in 2024. Globally, they expect AI datacentre power demand to rise by approximately 40 GW by 2026. These trends provide an important indicator about the criticality of this current moment: it is very much the beginning of the buildout.
The growth in AI datacentres is constrained by energy availability. There is not 40GW of spare energy capacity around the world, and so the cloud providers are taking steps to meet their power demands. Cloud providers have snapped up the limited amount of spare capacity it was possible to buy—for example, Amazon has bought a 960 MW nuclear reactor, and Microsoft has signed a 20-year power purchase agreement with Constellation Energy to reopen an 836 MW reactor at Three Mile Island. SemiAnalysis reports, “[T]he search for power is so dire, X.AI is even converting an old factory in Memphis Tennessee into a datacenter due to the lack of other options.” As an indicator of the intensity of the buildout: to create the power supply for this datacentre, x.ai…
“[P]ut a bunch of mobile [natural gas] generators usually reserved for natural disasters outside, add[ed] a Tesla battery pack, [drove] as much power as we can from the grid, tap[ped] the natural gas line that's going to the natural gas plant two miles away, the gigawatt natural gas plant…[and got] a cluster built as fast as possible."
This project was completed in 19 days, despite the fact that constructing a 100,000 GPU cluster ordinarily takes a year. (It also ordinarily costs $1 billion, but they were willing to spend $4 to $5 billion.)
To fuel further growth, the cloud providers are enabling the construction of new energy assets. Oracle has a permit to build three SMRs and Google announced a partnership which will give them seven SMRs to provide 500 MW for datacentres, starting in 2030. Amazon has partnered with Dominion Energy to build SMRs for datacentres. Most ambitiously, OpenAI asked the Biden Administration to construct between five and seven 5GW datacentre campuses across the US.
The exact level of capital expenditure on AI infrastructure (let alone on energy generation assets) is difficult to disaggregate from the earnings reports of big tech companies. This estimate suggests big tech companies will spend more than $100 billion on AI infrastructure in 2024, and SemiAnalysis estimates that Microsoft will independently spend more than $50 billion. Estimates of future capital expenditure vary from hundreds of billions to nine trillion dollars.
As with many things in AI, it is uncertain, but likely to be big.
4. The UK would power AI datacentres using nuclear power, not wind and solar
We investigated which source of power generation would be most suitable for AI datacentres in the UK, to determine where reforms should be focused. We compared two forms of low-carbon energy—nuclear power, or a blend of wind, solar, batteries backup, and natural gas reserve. We didn’t consider the possibility of using entirely natural gas to power AI datacentres, as we considered this incompatible with emissions aims, though it is a potential approach.
It is important to note that not only do AI datacentres need lots of power, but they need incredibly reliable power. Datacentres require high uptime—their service level agreements typically stipulate “five nines of reliability”, meaning the datacentre can have downtime of 5 minutes and 15 seconds over the course of a year. This effectively dictates the power cannot fail, as, this report notes “even a 25 millisecond power outage could take down the entire datacentre for several hours or even days”.
AI datacentres need reliability for two main reasons:
The current technical regime for training large models currently requires synchronisation between compute assets. If an AI datacentre is contributing to a large training run, and it goes offline during a training step, it will disrupt the whole training process.
Second, despite the power intensity of GPUs, electricity only makes up a small fraction of the ‘Total Cost of Ownership’: the monthly GPU server hosting costs are just $1872, while server capital costs are $7026. Therefore, having GPUs sit idle is much more expensive than building redundancy.
The renewables, batteries, and gas blend is impractically expensive, and undesirably polluting and land intensive.
To think about how the optimal blend works; it makes sense to layer on the tradeoffs. First, wind and solar are highly intermittent, and so getting consistent output requires building much more than would be naively estimated. (A 1GW solar plant will only actually give you 1GW in the most fleetingly intense moments of the summer, most of the time it will fall below.) Next, because it is sometimes windy when it is not sunny, and sunny when it is not windy, we say that wind and solar have covariance, and so there is always value in having some of each in the mix. Solar and wind are roughly as cheap, so cost is not a major determinant of which to choose.
There will be moments throughout the day when it is neither sunny nor windy. For these it is necessary to employ batteries. This does not fully solve the problem, because sometimes there will be low wind speeds and clouds for a week, and while this could be solved by building complete battery backup, it becomes enormously expensive. Batteries are cost-competitive if they are being used constantly (roughly every four hours), but they are expensive to sit idle, and so while batteries are efficient for overnight use, it is impractical to use them for a longer period. For extended periods where wind speeds are low and it is cloudy, it is necessary to use a natural gas backup.
We estimated that the cost-minimising way to use a blend of solar, wind, batteries, and natural gas; for every 1 GW of stable output, it would require 8 GW of solar panels, 0.37 GW of wind power, 12 GWh of battery-backup, complete gas-backup, and LNG import capacity of 451 million cubic metres of gas. (Our method is included in the Technical Appendix.)
This presents a number of challenges:
The land use. Building 8GW of installed solar and 0.37GW of wind capacity would require 160km2 and 41km2 respectively. (We assume the wind is onshore, as costs offshore are harder to predict as getting energy back to shore is more difficult).This means that each gigawatt would require more than 200km2 of contiguous land. As a point of reference, Cardiff is 140km2 and Reading is 40km2. This scales very poorly. Some datacentre campuses are much larger than one gigawatt, for example, imagine that Microsoft and OpenAI’s 5GW datacentre campus was powered by renewables in the UK, it would require over 1000km2 of contiguous land.
The land would need to be next to LNG import capacity. The UK has three LNG import terminals, one in Kent and two in South Wales. The natural gas generation terminal would need to be some distance from population centres to reduce air pollution, but also close enough to the import terminal that gas pipelines are not necessary. It is either necessary to find ways to build these generation facilities in Kent or South Wales while being contiguous with the solar and wind farms, or it might be necessary to build a new LNG import terminal, but neither approach scales well, and the latter would add substantially to costs.
Emissions. As natural gas would generate 28% of the electricity, over its expected life cycle, the renewable blend would produce 40% more carbon emissions than equivalent nuclear capacity.
Cost. The levelised cost would be £106/MWh. This would be internationally uncompetitive for creating an AI datacentre—the equivalent cost for Texas to produce energy with the same carbon footprint would be £74/MWh. Should emissions be desired to fall further, the output electricity would only become even more uncompetitively expensive.
Safety. Even when natural gas is only used 28% of the time, the mix leads to 27 times more ‘expected deaths’ per TWh (mostly from air pollution), when compared to the risk of accidents with nuclear power.
As a reminder, these numbers are for 1GW of consistent output, and global datacentre buildout is expected to be around 40 GW by 2026.22 It is probable to expect 10s of gigawatts of power demand in the coming years. Renewable approaches will not be able to scale to this level, and to provide the concentration of power required onto the largest datacentre campuses.
Nuclear is more suitable because it is reliable and safe
Contrary to wind and solar, nuclear power has very stable output, which is ideal for meeting the ‘five nines’ requirement that datacentres have – 99.999% reliability.23 The US has a nuclear capacity factor of 92.5% as a benchmark. The chart below shows US total energy generation in a week in March last year; note that nuclear is the green block at the bottom—extremely stable!

Furthermore, there has been an international realisation that nuclear power is safe, clean, and necessary to meet climate goals. 20 countries at COP 28—including the US and UK—announced their intention to triple global nuclear energy capacity by 2050. The world’s biggest investment banks have announced their intention to finance this aim, Italy and India announced plans to accelerate the construction of nuclear power, and Japan is looking to reopen 13 nuclear reactors. Since then, the US has said it will add 200 GW of nuclear power by 2050.
A negative perception of nuclear energy has come from its association to nuclear weapons, and the infrequent-but-visible reactor meltdowns and subsequent evacuations. The Pripyat Ferris Wheel and empty swimming pool have a prominent effect on our collective psyche towards nuclear energy safety, but we have no similar association for the Banqiao Dam Collapse which killed 171,000 people in 1975.
When compared to other sources of energy, especially practical stable generators alternatives, nuclear power is comparatively much safer and cleaner per TWh of generation.

There have been three high-profile reactor meltdowns: Three Mile Island (1979), Chernobyl (1986) and Fukushima (2011). The meltdown at Three Mile Island caused no deaths either directly or indirectly, and the radiation exposure for 2.2 million people who lived near to the New Jersey plant was, “approximately the same radiation dose as flying from New York to Los Angeles”.26
Our World in Data, an independent research organisation, has reviewed the death tolls for Chernobyl and Fukushima. Their literature review estimated the Chernobyl meltdown caused between 300 and 500 deaths; 30 direct deaths, and the remainder were indirect. At Fukushima in 2011, there were no direct deaths in the disaster. There were 40 to 50 injuries, and 7 years after the accident, it was reported that one worker died from lung cancer caused by radiation exposure at the event. However, there was a mass evacuation, which is estimated to have caused 2,313 deaths, from the physical or mental exertion of evacuation (from care homes and similar places). Disentangling which of these deaths were attributable to the evacuation following the meltdown, compared with the wider impact of the earthquake and tsunami, is necessarily difficult.
There is a particular dissonance between attitudes to fossil fuels and nuclear power. Unlike nuclear power, fossil fuels are continuously and gradually reducing the life expectancy of billions of people, but there is never a discrete moment where this is felt more acutely. This report notes that, “moving to Tokyo would triple the populations’ increase in risk of death [because of air pollution], compared to moving them back to the remaining off-limits zones in Fukushima.” This paper estimates that the slowdown in nuclear power construction following the Chernobyl meltdown caused the loss of 33 million expected life years in the UK alone, or roughly 400,000 people, because of particulate poisoning.
To summarise, the UK will not be able to produce cost-competitive renewable energy for AI datacentres, that scales to the 10s of gigawatts required. However, nuclear power has all the necessary attributes—it is cleaner, safer, has more reliable generation—and as we discuss in a further section, could become internationally cost competitive too.
5. Going without AI datacentres would be a mistake
A sceptical line of argument might say that while AI progress is happening; and AI datacentres and power will grow dramatically; and nuclear power will be the dominant energy source; it does not necessarily follow that the UK should be concerned with hosting AI datacentres. The strongest form of this argument claims: the pattern of economic history is that the gains from general-purpose technologies tend to come from adoption, and perhaps UK residents and businesses could buy access to AI datacentres internationally, while the UK could focus on the ‘highest value’ parts of the AI value chain.
This argument is not enough—going without AI datacentres would be a mistake. The economic doctrine that the UK can sit atop the value chain, and selectively choose to engage with ‘high value’ industries has led to a hollowing out of industry, and left the UK without growth. Hosting AI datacentres will enhance the UK’s economic security, allows directed growth into former industrial areas, and enables future frontier growth.
A large fraction of the UK’s capital stock will be in AI datacentres
It is very likely that computational power becomes a critical input into the production of goods and services, in a manner similar to energy. Just as the venture capitalist Marc Andreessen commented in 2011, ‘software is eating the world’, the information processing capabilities of AI systems will become tightly knit into all existing business processes and future ones. This will be especially true for the UK’s professional services exports. As a result, a very large fraction of the UK’s capital stock will be created, stored, and run in, or at least depend upon, AI datacentres. The UK will want these AI datacentres to be here, rather than overseas, connected through an undersea cable, to ensure it can protect these assets.
Furthermore, precisely because the gains from AI come from adoption, the UK needs to ensure access to computational power. As demand for computational power rises globally, it could be the case that UK businesses are unable to access the computational power they need. Right now, the Microsoft CFO said on a recent earnings call that revenue growth in their cloud business was 33% but, “[d]emand continues to be higher than our available capacity.”
For decades, the UK decided to go without energy self-sufficiency. It would be imprudent to repeat the same mistake for computational power.
Directing growth to former industrial areas
The work to adopt and develop AI applications is likely to centre around London. The Government’s AI Sector Study shows that 75% of UK AI companies are based in London, the South East, or East of England. AI application developers are likely to agglomerate here because London has the best venture capital ecosystem and AI talent density outside San Francisco. Furthermore, adoption of AI systems is likely to focus on automation of business processes in professional service domains and scientific endeavours initially, which is also likely to begin within the ‘Golden Triangle’.
AI datacentres do not depend on network agglomeration in the same way. The construction and operation of these datacenters can be much more readily directed, to areas outside the Golden Triangle with strong industrial traditions. Very rarely does the opportunity of investment which is location-independent come along. There can be thousands of skilled jobs in the nuclear and datacentre construction and operation industries.
Furthermore, there are spillover benefits from developing these industries. UK workers will learn how to build nuclear reactors from the Korean Electric Power Corporation, who construct reactors for 25% of the price; or how to build AI datacentres with a Power Usage Effectiveness of 1.1, from Google.
If the UK wants to participate in the frontier growth of the future
The UK has enormous strengths in science, through its world-leading universities and research institutes. The process of research and development is likely to be transformed by AI systems in the coming years, and so maintaining the UK’s scientific advantage and the prospect of future growth it offers is likely to require differential integration of AI systems into the research cycle. It seems very likely that future UK growth will be downstream AI-enabled scientific discoveries, for example, new drug discoveries from future versions of AlphaFold. In such cases, computational power will be a critical input—it is not sensible to solely depend upon international markets for a resource which is so central to future prosperity.
Simply, AI datacentres are an asymmetric bet—if the AI ‘bulls’ are correct, then it is crucial the UK has datacentres for future growth and security, and it is crucial the UK expands its compute industry. If the ‘AI bears’ turn out to be correct, the rollout of AI systems will be a multi-decade-long integration of a general-purpose technology and so operating the AI infrastructure will provide jobs and tax revenues for public services; as well as spillovers in knowing how to build cheap power generation in the UK. As private investors are providing the capital, there is no scarce resource being consumed by creating the conditions for them to invest. The bar for deciding to pursue AI datacentres and nuclear power generation is low, as the UK needs growth so dearly.
6. Nuclear power is slow and expensive to build, but it could be cheaper and faster
UK nuclear power construction is really slow and expensive.27 No private investor who wants to power an AI datacentre would choose to build a nuclear power plant in the UK, at present. However, there is a truly remarkable amount of low-hanging fruit to be picked, to become internationally competitive.
In this section we diagnose the reasons for the high costs, and in a later section, we propose a reform package based on this diagnosis.
To set the scene:
Hinkley Point C is forecast to cost £10 million per MW, which is 4.5 times more expensive than South Korea, £2.24 million per MW.28
Construction for Hinkley Point C has been delayed to 14 years, from nine years planned. Sizewell C is due to take 12 to 15 years to build. On the contrary, the median time to build a nuclear reactor since 1990 has been under six years. Between 1970 and 2009, Japan built 60 nuclear power plants in a median time of 3.8 years
Hinkley Point C took six years to progress from initial consultation to final approval. The consultation process for Sizewell C began 12 years ago, and EDF will make a final construction decision in Spring 2025. By comparison, France and France took just three years and four and a half years respectively to approve a plant with the same reactor (the European Pressurised Reactor, or EPR-1600.29
Three UK projects have been abandoned in the pre-construction phase since 2018 because of financing concerns.30
The total cost of nuclear power is halved if you can borrow cheaply
The most important thing to understand about nuclear power projects is that the cost of capital dominates the overall cost of the project. Interest was approximately two thirds of the cost of Hinkley Point C.31 This report estimates the breakdown of Hinkley Point C costs as follows:

The cost of the electricity is very sensitive to the cost of borrowing for construction: a 2020 report by the International Energy Agency uses a prototypical EPR-1600 in France, and says when the cost of capital is 3%, instead of 10%, the levelised price of energy is reduced by more than half (53%).32
Why does this matter for our purposes? There are two implications:
Speed matters; not just because the energy generation can begin, but because it means borrowing can stop.
Certainty matters; when investors perceive a project to be less risky, the more cheaply they provide their capital. This report said EDF were forecasting a 9% return on their capital at Hinkley Point C.
Any reforms to planning and regulation not only save money directly through simplification, but they also reduce project risk and timelines, thereby leading to indirect savings on interest payments.
Construction costs can be halved again by building reactors ‘in fleets’
South Korea is able to build nuclear so cheaply because it builds reactors ‘in fleets’, where it repeats the same reactor design of reduces its cost of nuclear power by building ‘fleets’ of 8 to 12 times. This repetition creates ‘learning’ between projects. (Learning describes the cost declines driven by the cumulative experience of having done something before.) The clearest example of learning is performing technical tasks better. Because nuclear power plant projects are so large, these gains even exist within projects: EDF has claimed that welding for the second reactor at Hinkley Point C is happening twice as quickly. But an equally important type of learning comes from the developers knowing what the regulators want—construction is only a small fraction of the activity to start a nuclear reactor, lots of effort is spent on quality assurance and safety. When a reactor is repeated multiple times, the mutual understanding between regulators and developers transfers across projects.
Fleets also support supply chain certainty. The nuclear supply chain requires higher quality assurance standards and more intensive component testing than ordinary industrial projects, which often necessitates a separate supply chain. If there is a large number of reactors to be built, which have been approved previously, the nuclear supply chain could produce components without needing to specify in which specific reactor the parts will be used. The same applies for the supply chain of skills. When there is a clear pipeline of construction projects, investing the time to become a nuclear welder is a sensible career choice, as it will raise wages for the long term.
The UK does the opposite of building in fleets. The last UK nuclear project to be completed was Sizewell B, in 1995. This reactor was a Pressurised Water Reactor, and it would be 21 years before construction on our next nuclear reactor began at Hinkley Point C. This was a different design, the EPR-1600. As we’ve noted, this basic reactor design had been used previously in France and Finland, however EDF has said the Office for Nuclear Regulation (ONR) required 7,000 design changes including 25% more concrete and 35% more steel for the reactor to be approved in the UK. The ONR disputes this, but irrespective of who was responsible, when the reactor becomes increasingly dissimilar, it is evermore difficult to transfer learning from the previous sites.
The combination of low levels of regulatory certainty, and no clear precedents for the one-of-a-kind reactor, mean that the supply chain might not have the confidence to justify preparing components until after the final construction decision is made. Likewise, with large gaps between projects, the ‘supply chain of skills’ is weaker: workers have lower incentives to develop the skills required for nuclear projects, and move away to other professions. For example, the delays to the approval of Sizewell C mean that nuclear welders will be unable to transition from Hinkley Point C directly into a new project.
The nuclear approval process is vetocratic—there is no positive force in the system to push back against time delays and cost increases.
The next largest contributor to slow and expensive nuclear projects is the diffusion of state responsibility for approvals. For a new nuclear power plant to be approved:
The Office for Nuclear Regulation must grant a Nuclear Site Licence, which covers the location, the technology, and operation against accidents. The ONR is an independent statutory authority, and a public corporation in the Department for Work and Pensions.
The Environment Agency must grant an Environmental Permit to cover the environmental effects of operation, if the reactor is in England; and in tandem with the respective devolved administration if it is elsewhere.33
The Secretary of State in the Department for the Environment, Food, and Rural Affairs must confirm regulatory justification, which states that the benefits of using ionising radiation outweigh the costs.
The Secretary of State for the Department for Energy Security and Net Zero must approve a Development Consent Order (DCO), which involves multiple rounds of consultation and an Environmental Impact Assessment (EIA).
The ONR is an independent statutory authority, responsible for nuclear fission safety. This means its mandate and responsibility is to prevent accidents that could be caused by nuclear power plants. The ONR has no authority or responsibility, to weigh the counterfactual risks from not building nuclear power: for example, the approximately 33 million life-years lost in the UK due to air pollution since nuclear power plant construction was slowed following Chernobyl, or the environmental damage from ongoing greenhouse gas emissions, or the impact of high energy prices on people or businesses, or any manner of other challenges.
The incentive and responsibility of the ONR is to minimise the risk of accidents from nuclear. The global standard for safety regulation, required in all industries in the UK, is that the risk of ionising radiation exposure is ‘As Low As Reasonably Practicable’ (nb. in some contexts this might be ‘As Low As Reasonably Achievable’). Because the ONR is not set up to balance aims, such reasonableness is defined as anything which can improve reactor safety, until a measure can be proven to be ‘grossly disproportionate’.
Similarly, the consequences of long and uncertain Environmental Impact Assessments are not considered. The EIA for Sizewell C was 44,260 pages; and for Hinkley Point C it was 31,401 pages. The issues of EIAs are not unique to nuclear power, and so we leave these to other sources, however, a report by Sam Dumitriu claims that EDF have spent, “hundreds of millions [of pounds]”, at Hinkley Point C to install underwater speakers, in order to deter roughly 112 fish from entering the water cooling system.
Unlike the UK, in South Korea, the Nuclear Safety and Security Commission reports directly to the Prime Minister.34 This report suggests that political oversight changes the incentive equilibrium for regulators, to more appropriately balance the costs and benefits of incremental safety regulations. Though the ONR is independent, it is also a public corporation within the Department for Work and Pensions, and therefore there is less Ministerial interest or bandwidth for seeing that nuclear power gets built.
‘Regulatory justification’ has been misapplied
‘Regulatory justification’ is a requirement that stems from a 1996 EU directive that stipulates the benefits of ionising radiation for the production of energy must outweigh the costs. This does not seem, in principle, to be a bad idea—who would be for using ionising radiation where the costs exceeded the benefits? However, the requirement applies to each ‘practice’, which is an instance of the use of ionising radiation. It is currently interpreted that each reactor design is its own practice which must be separately assessed for regulatory justification. There are good legal arguments that nuclear power, or broad characteristics such as using low enriched uranium and light water as coolant and moderator, should be a single practice for which ‘regulatory justification’ is established once and for all.
Because of ‘functional separation’, authority for this decision sits with the Department for the Environment, Food, and Rural Affairs, and the decision takes two years. This is duplicative, because the purpose of the planning process is to weigh the relative merits of a new project. France, Finland, and Sweden incorporate the ‘regulatory justification’ into their planning decisions.
This superfluous step increases project uncertainty and duration and therefore raises the total costs of the project by causing longer and more risky borrowing.
To summarise, there are many actors in the system who can say ‘no’, or who might add incremental delays and cost increases to nuclear power plant construction, which amounts to a de facto ‘no’; but there is no positive force which pushes back against slowness, expensiveness, and the counterfactual damages of the two. With an approach that weighs cost and benefits, including the knock-on impacts to speed and certainty, the UK can build an internationally competitive nuclear planning and regulatory regime.
7. The UK should create ‘Special Compute Zones’
The purpose of this reform proposal is to solve an incongruence:
The UK’s AI datacentre capacity is an imperative for economic security, growth in former places of industry, and long-term prosperity; as this previous section set out.
But the planning and regulatory approval process for building new AI datacentres and associated power cannot permit the amount of construction, at the speed required.
Below is our proposal on how this might be resolved.
Within ‘Special Compute Zones’, there is an alternative planning and regulatory approval process for nuclear reactors, AI datacentres, and the transmission and networking infrastructure they require. The goal is to provide the certainty, speed, and hence, the opportunity to be cheap, that would make the UK the most competitive place in the world to build AI datacentres.
Within the Zones, there would be ‘deemed consent’—meaning the default answer to construction is ‘yes’—and permission to construct would have to be challenged within three months of an application. Ordinarily, planning decisions weigh the relative merits of each project; but within a ‘Special Compute Zone’, it would be decided that by creating a zone, this cost-benefit has already been considered, and therefore approval would depend on a ‘condition-based approach’. This means that if a developer can prove the project meets particular standards, it goes ahead. There is precedent for location-based policies from Spain and the EU.35 In Spain, the Government passed a decree which allowed renewable projects to forego the Environmental Impact Assessments, so long as the project met some conditions:
Wind and solar projects are below 75 MW and 150 MW respectively.
Projects are in areas of low or moderate environmental sensitivity.
Grid connection lines are not longer than 15km or above 220kV.
Authorities do not lodge an objection within two months.
This report notes the change doubled the speed of projects, and increased the forecast of solar construction by 13GW for 2030.36
The EU has mandated “Renewable Acceleration Areas”, as of September 2023, which require Member States to designate at least one area by February 2026. To implement them, Member States prepare, “a mitigation ‘rulebook’ consisting of a set of rules on mitigation measures to adopt in the specific area, aimed at avoiding or where not possible significantly reducing the environmental impacts resulting from the installation of projects in those areas.”
The Secretary of State in the Department for Science, Information, and Technology would be able to provide a single sign-off for the projects. This means nuclear power, AI datacentres, and networking and transmission infrastructure would be approved together, to improve project certainty. As with renewable zones, developers would apply to the Secretary of State, who would have three months to object to the application for construction, after which the project would automatically have permission. This aligns the incentives of governments to quickly respond to applications, as the average consideration period of a Development Consent Order is 22 months.37 Furthermore, a non-objection procedure, rather than a positive decision on each site, reduces the risk of judicial review. Judicial review proceedings could slow construction by roughly two years; and so developers are likely to want clarity that everything possible has been done to avoid judicial review. In order to further reduce the risk of judicial review, the primary legislation for Special Compute Zones could:
Specify the grounds on which a challenge to the Act can be brought.
Exclude “oral renewal” for judicial review.
Ensure reviews are brought for procedural reasons and not ones based on the principle, policy or merits of the proposal.
One area for further investigation is to what extent all of the application process needs to be frontloaded before construction can begin, or whether this can be parallelised. For example, some environmental permitting and mitigation (i.e. dealing with environmental effects of plant operation) might be performed concurrently with construction, subject to a condition that the plant cannot start operation until they have been addressed. There is international precedent for this: nuclear power developers in the US can opt to licence their reactors through ‘Part 50’ of the U.S. Code of Federal Regulations, which grants them separate construction and operating licences. (Ordinarily developers use Part 52, which grants construction and operation licences together.) The developer takes on some risk that they aren’t granted an operating licence, when they begin construction without.
The “Special Compute Zones” will need to permit nuclear power operators to make ‘behind the meter’ power purchase agreements with datacentre operators. The grid network fees are 20-25% of the cost of grid power, and so it is necessary to make the UK a competitive place to build.
How should the Zones be designated?
The primary legislation for Special Compute Zones could designate all former nuclear, coal, and natural gas power plant sites, former steel plants, and ports as Special Compute Zones, and give the Secretary of State the power to de-designate or designate individual sites or classes of sites. The primary legislation would need to designate sufficiently broad classes of sites to avoid being a hybrid bill. This is because hybrid bills have a much longer parliamentary process, and therefore would take much longer to pass, and so it would make it much more difficult for the UK to participate in building AI datacentres. By making all of these classes Special Compute Zones through primary legislation, and providing the Secretary of State power to object and de-designate, the risk of judicial review is considerably lower than if the Secretary of State had to make a decision to designate each particular site. This in turn, means it is more likely that AI datacentres would be built.
The Secretary of State should also be given the power to determine which environmental conditions apply to each zone, based on a high level environmental assessment, so that environmental protection is provided. Compliance with those conditions would, under the Act, be a basis for removing the need for EIA.
Former sites of energy generation and steel production are especially suitable to be Special Compute Zones as they have grid connections and previously had environmental impacts that are likely equal to or, indeed, much greater than nuclear power plant operation. This improves the ease and strength of argument for streamlining the regulatory and planning process. Ports are suitable for conventional nuclear because bringing materials to the site by boat is substantially easier than to other sites. For example, at Hinkley Point C, wharfs needed to be constructed for delivery to reduce the number of lorries.
There may be additional options for planning and regulatory approval, worth including as alternative pathways, although they are unlikely to deliver results within the necessary timeframes as the proposal suggested above. For example, the local planning authority could grant consent for new nuclear power and datacentres, provided the application met the conditions required by the Special Compute Zones. To incentivise local governments to allow more power and datacentres, they might be permitted to retain 100% of the business rates in perpetuity for projects approved by this mechanism.
What should the conditions be?
For deemed consent to apply, the reactor must have been approved by a recognised international regulator (i.e. the US or the EU). Introducing international recognition would speed up both approval and construction.38 Practically, international recognition would allow international teams who have already built fleets of reactors to come to the UK, upskill local workers, and replicate their previous work, saving costs with the lessons they learned during that work.
The conditions for radiation dose exposure for workers and the public could be taken from the Ionising Radiations Regulations 2017.
Some conditions would relate to environmental impacts of construction and operation, to streamline and replace environmental permitting and impact assessments, and could include options such as requiring the developer to pay into a rewilding fund. This will ensure environmental effects are addressed without creating uncertainty and expensive delays.
Some conditions would address questions generally addressed in Nuclear Site Licences. For example, there should be requirements about emergency planning in scenarios with technical failure, and population density around the site.
Crucially, these conditions should differ between conventional nuclear and SMRs. For example, safety requirements should be proportionate to the size of the plant.
How should we deal with ‘regulatory justification’?
Because regulatory justification is an EU directive, it would either need to be incorporated into a planning decision, per the French, Finnish, and Swedish approach, or it could be addressed by a Regulation 9 decision declaring all classes of nuclear power as a new justified practice or issuing a Regulation 12 determination that nuclear energy is an existing practice due to the operation of Magnox, Advanced Gas Reactors, and Sizewell B before the introduction of the directive.
Technical Appendix
The model solves for the optimal solar, wind and gas combination to minimise the levelised wholesale cost of electricity.39 The model generated 100 possible sets of 365 days outputs of solar and wind, and optimised the selection over 4000 possible combinations of solar, wind and batteries output.
Solar
Solar energy has two sources of variance in the model - one caused by variation in average output across months and the other caused by daily variation caused by cloud cover and similar. Average output varies due to the northern hemisphere tilting away from the sun in winter - which both directly reduces incidence by trigonometry but also indirectly does so by forcing sunlight to pass through thicker air before reaching the Earth’s surface. Average solar output in December is thus 72% lower than its level in summer - with this effect being much greater than temperature variations imply as air can move around the earth. Cloud cover also reduces output, giving daily variation following a gamma distribution with shape 3.5. In the UK, solar energy has a capacity factor of 10%, a levelised cost of £49/MWh, and 1GW occupies 20km2. In Texas, the levelised cost ranges from $24 to $96, giving a central estimate of $46/MWh. Solar output in Texas is much less volatile, declining by only 40% in winter.
Wind
Wind energy varies in output due to variations in wind speed, which occur both across days and seasons. During winter, UK wind speeds are 25% higher than summer, giving it the beneficial property of being weakly negatively correlated to solar. However, the underlying energy stored within wind goes as the cube of wind speed, as each individual molecule’s kinetic energy goes as the square of wind speed and linearly more air molecules hit the turbine’s blades per second as wind speed increases. Although wind power in practice hits diminishing returns and eventually decreases in power output in wind speed, for most of the wind speed distribution in the UK we remain in the cubic - and so highly volatile - portion. This is compounded by the high volatility in the underlying distribution - Rayleigh, with a standard deviation of half its mean. In the UK, wind has a capacity factor of 27%, a levelised price of £53/MWh and 1GW of wind occupies 110km2. The cost ranges from $24 to $75, implying a central estimate of £38/MWh.
Batteries
Batteries offer the ability to smooth variable-output processes and provide the constant stream of power needed for efficient datacentre operation. Additionally, as they are primarily used in summer the scale-up of solar over the day still only means 12GWh are required for continuous operation. However, they still remain impractically expensive to participate in balancing on timescales longer than a day, and also remain limited by generally only being able to charge at the same rate as they discharge - meaning that very large amounts of excess generation by renewables across seasons is difficult to exploit. Existing grid-scale storage has a price of $400/MWh and lasts for at least 2000 cycles.
Gas
Gas has a levelised price of £136/MWh, just over half of which is carbon pricing. The capacity factor is close to 100%, and the area occupied is very small in comparison to renewables. In Texas, the cost is $39-$68, so a central estimate of £41.
Results
In the optimal allocation, 8GW of solar and 0.4GW of wind was procured, at a cost of £106/MWh with 28% of electricity being gas generated. If it was possible to sell to the grid at £30/MWh during periods of renewables surplus (plausibly too high for the unsubsidised price as this is so correlated nationally), then the optimal solar quantity rises to 12GW, the optimal wind quantity stays unchanged on 0.4GW and the carbon intensity drops to 0.17GW, and the levelised cost drops to £98/MWh. The levelised decline is so small in response to the grid connection because the previous allocation only wasted 18% of its total output as curtailed renewables, so without a large adjustment on the renewables side (which are unprofitable without a guaranteed price on sale induced by subsidies) this leads to little change in prices. Given that the grid connection would of course have to be built and maintained, this renders its provision unlikely to reduce overall costs. Total expected deaths/GW-year are 7.06. The cheapest equivalent-emissions option for Texas costs £74/MWh, being composed of 0.7GW of wind and 4.7GW of solar. If Texas faced the same carbon pricing as British gas, the cost remains substantially lower at £89/MWh.
This is different from ‘ordinary’ computing, which can only do exactly and specifically what its program (a pre-set instruction for information processing) tells it to do. On the contrary, AI systems, more like brains, are able to learn and have flexible and adaptive information processing.
From the 95.6% raw percentage score would typically fall in the 99th percentile of LSAT performance.
The average energy consumption of a UK resident annually is 4,266kWh, an H100 chip would use 6,132 kWh. The next generation B200 chip would use 10,512kWh over the course of a year (assuming continuous running).
OfGem has a medium-sized household using 2,700 kWh in electricity annually, then 27 MW of installed power capacity is 87,600 households.
The UK produced 310 TWh of electricity in 2021, and 100 GW of generation running for 9.12 months would produce 665.18 TWh of power.
Over the course of a year, a 1GW datacentre will use 8760 gigawatt-hours (GWh) of power, but across both industry and domestic demand, Liverpool used just 1696 GWh in 2022.
The CfD was £92.50/MWh in 2012 prices, and there has been 54.5% inflation since, meaning 2024 prices are £142.83/MWh.
Potentially including the scientific research which goes into the creation of better AI systems, though exploring the details of this possibility is beyond the scope of this report.
The definition of superintelligence is necessarily weaker, as we are less confident about what such a system would look like.
This paper reviews the arguments for and against, and this report by a former OpenAI employee makes the case for how AI systems would soon become capable of supporting explosive growth, while noting potential bottlenecks.
Technically, language models are trained to predict ‘sub-word units’ called ‘tokens’, hence why this task is sometimes referred to as ‘next token prediction’.
It is a common discussion point to debate whether a neural network’s prediction constitutes ‘true’ understanding. Given the enormous downstream capabilities of the models already mentioned, it seems to us to be quite clear important things are happening inside the models, and semantic debates have tended to take the oxygen from more pressing questions about how to integrate powerful systems into society.
It is worth noting that improving the energy and computational efficiency of hardware will induce further demand for hardware. It is a Jevons Paradox. (Efficiency might usually mean reduction, but this is not the case.)
The average energy consumption of a UK resident annually is 4,266kWh, an H100 chip would use 6,132 kWh; and a B200 chip would use 10,512kWh over the course of a year (assuming continuous running).
There were 85492 households in York, at the most recent census.
Context: the UK produced 310 TWh of electricity in 2021, and 100 GW of generation running for 9.12 months would produce 665.18 TWh of power.
The growth rate in “AI datacentre critical IT power” between 2026 and 2027, and 2027 and 2028, using this SemiAnalysis report, is 46.9% and 36.2% respectively.
There is some variability based on operational practices—per this article, “South Korean plants are five times less likely to lose capacity due to unplanned outages than UK plants”.
This section draws on the work by Britain Remade, a think tank for economic growth. We are grateful for their high-quality work on nuclear construction that has informed a lot of this proposal, we link to their work where appropriate.
Note that EDF is paying for construction, not the taxpayer. The government agreed a CfD with EDF to provide energy at £92.50/MWh in 2012 prices.
Wylfa, Moorside, and Oldbury.
There is not a publicly available breakdown from EDF, but the International Energy Agency published a report in 2020 which said the overnight capital cost (i.e. exl. interest) of building a European Pressurised Reactor (the reactor used at Hinkley Point C) is $4013/kWe in 2018 USD. Exchanging to 2018 GBP (at 1:0.75) and adjusting for 2024 prices (26% inflation), implies an overnight capital cost of £6.26bn GBP 2024 for each reactor. The total project cost, adjusting for inflation is £41.31 billion to £45.31 billion in GBP 2024. Which suggests that 69.7% to 72.3% of capital costs is interest. From conversations with experts, this is on track with other estimates, though perhaps on the higher end.
Natural Resources Wales, the Scottish Environment Protection Agency, or Northern Ireland Environment Agency.
The organisation of the state in South Korea is different to the UK; the President takes an active role in administration.
h/t to Sam Dumitriu for highlighting this on his Substack.
Bloomberg NEF’s 2030 solar forecast was raised from 73GW in April 2022 to 86GW in October 2022.
Again, h/t to Sam Dumitriu for highlighting this on his Substack.
Once again, h/t to Sam Dumitriu for highlighting this on his Substack
Implicitly this assumes that exclusively cogeneration occurs as this allows transportation costs to be ignored - meaning that wind is considered exclusively onshore not offshore.
 | A guest post by
|
 | A guest post by
|
 | A guest post by
|