


How much economic growth from AI should we expect, how soon?


Is this the steam engine, electricity, computers, or something bigger?
General-purpose technology revolutions have been the fundamental driver of human prosperity in the last 300 years.1 That these revolutions have raised the living standards of billions of people would surely indicate that, on the arrival of a new general-purpose technology, the forces for adoption must cause the world to change very quickly. But this could not be further from the truth!
The first commercial power station was built in 1882, and it was not until 1920—nearly four decades later—that electricity surpassed steam as the dominant form of horsepower in the US economy.2 In similar fashion, the microprocessor was released in 1971, but in 1990, just 20 million personal computers were sold. Among households, the pattern was consistent: reaching 50% adoption of electric lighting and a PC for the family, both took 30 years.
In the data, too, the effects are drawn out: the steam engine contributed 0.2% per year to productivity growth for 20 years, and then 0.38% per year for another 20 years in the mid-19th century.3 The largest effects on productivity from electricity took 40 years to materialise4; and similarly, Robert Solow famously commented, “computers are everywhere but the productivity statistics”, which held until they finally showed up in the mid-1990s.
The important question, for our purposes, is to what extent should we expect artificial intelligence to be “just another general-purpose technology” — where growth effects very gradually over decades — or should we regard making intelligence as qualitatively different from previous revolutions?
Executive Summary
The view in San Francisco is that AI will far exceed the pace and depth of change in all previous technological revolutions. This is because of a belief that AI can automate the process of invention itself. Since Bacon, the march of science depended on the actions individual inventors and small groups of researchers; but perhaps in a few years, we can create AI systems that will be capable of performing research at the level of — or indeed, much better than — the best human researchers. We can put tech progress on autopilot.
How does this arise, according to this view? First, the AI labs create an AI system capable of performing AI research, on par with their top researchers. Next, millions of instances of the ‘digital AI researcher’ are run to make much faster research progress. These breakthroughs are applied to training the next generation of digital AI researchers, in a recursive self-improvement loop. This process leads to the creation of digital AI researchers which are much smarter than humans—this is ‘superintelligence’. In the dominant intellectual paradigm in San Francisco, this happens quickly. One important work on ‘takeoff speeds’ towards superintelligence argued that the time between AI systems capable of performing 20% of tasks humans do, and 100% of tasks humans do, was just four years.5
Superintelligence, as it is conceived, would have important implications for the economy: we could have an ‘explosion’ in R&D; and systems capable of performing 100% of the tasks that humans do could begin to automate the whole economy. (As the narrative goes, the superintelligence could figure out how to make robots which could perform as well as humans.) There is some academic work which investigates what happens to economic output when 100% of tasks are automatable, and many growth theory models show explosive economic growth (20% per year, or more).6 Under some conditions there is an economic singularity, which means growth models predict infinite output in finite time.7
On the contrary, most economists who study the impact of AI do not consider the prospect of recursive self-improvement. But most work on explosive economic growth does not deal with the microeconomic constraints of running an AI lab. This is a gap we hope to fill—providing a grounded view of what AI research automation will look like, and how this might come to affect R&D and cognitive labour automation in the near future.
AI research automation
The most important thing to understand about AI research automation is that the AI labs are constrained by computational power to run experiments, not by researchers. A researcher from the Gemini team at DeepMind has said, “I think the Gemini program would probably be maybe five times faster with 10 times more compute or something like that”. While the cloud providers are spending enormous amounts on compute—Microsoft just announced it would spend $80 billion this year on building AI datacentres—most of this compute would be used to run inference for customers, and is unlikely to be for AI researchers to run experiments. The economics of inference for customers is very different from the economics of compute for R&D: compute for experiments and training needs to be amortised across all of the inference profit margins. As we shall see, there are strong headwinds to making money selling tokens!
One of the assumptions which proponents of the Explosive Growth view often make is that a digital AI researcher will be trained on a large compute cluster, and then millions of instances will be run on the same cluster. This seems irregular to us! If the point is to recursively self-improve the AI system, but the training compute is being used for inference, where is the next generation agent going to be trained? It seems much more reasonable to imagine that ~60% of the AI labs' compute goes on serving customers, ~30% goes on training the next model, and ~10% goes on experiments. (These numbers are extremely rough guesses.) If the AI lab wants to run instances of the digital AI researcher, they will need to trade this off against experimental compute; and remember, research output is bottlenecked by experimental compute. If the digital AI researcher has equivalently good or worse ideas to the best human researcher, it makes sense to run zero copies; for it to make sense, the ideas have to be better.
AI research will be automated in the future. It is reasonable to imagine that, perhaps soon, we will create a ‘digital AI researcher’ whose research intuition—i.e. ability to predict which experiments will work—surpasses that of the best human researchers, but before then, digital AI researchers will have a bounded impact on research output, owing to the compute bottleneck. We discuss the practical challenges to increasing research output, as well as some reasons our mainline case could be wrong, in greater detail below.
R&D automation
Concurrent to our progress on AI research automation, we want to make progress in other fields of science and technology! The opportunity is enormous—for biomedical research, clean energy, materials, synthetic biology, nanotechnology, and robotics. As with AI research, the goal is to create systems which are capable of performing all steps of the research process—generating hypotheses, designing and running experiments, and interpreting results. There are a number of challenges to scientific automation, related to the availability of data, the necessity of real-world experimentation, and so forth. It also seems reasonable to believe that academia is poorly configured to take full advantage of the opportunity which AI automation is. We expand in greater detail on both points below.
We focus on three potential fields for automation—chip research because if we are compute bottlenecked, improving our chips would help to alleviate this; robotics as improvements here could begin to automate more physical labour, and biomedical research; for effects on human wellbeing. There are different challenges in each area to automation, though in general, experimental throughput is most likely to be rate-limiting.
Cognitive labour automation
Thus far, chatbots and ‘agents’ have struggled to meaningfully increase the productivity of human cognitive labour. Deploying systems is difficult right now—it requires specialised knowledge about how to build infrastructure for models. But as the models become increasingly capable of acting on long horizons, we expect most of the challenges to deployment to become diminished. We will still require people to have liability for AI systems, and in many professions, there are ‘embodied’ complements to cognitive tasks (e.g. when a doctor has a consultation, they are both doing the diagnosis, and tailoring their explanation to the patient, and expressing care and empathy, and so on) These factors together lead us to expect that people will be managing teams of agents in their jobs—it will look like ‘a promotion for everyone’—rather than a lot of job losses. However, there might be some areas where production is entirely substitutable, and so jobs might be lost. To estimate the increases to output from tasks being handed off to agents, we built a growth model that shows how many tasks might be automated, how much these tasks can replace other tasks, how cheap these AI systems are, and how concentrated this is within sectors. We find that growth will be quick by historical standards, but not explosive. We expect AI will provide a 3%-9% increase to economic growth per year in the near future, and we expect it will be in the lower end of this range due to bottlenecks we discuss further in the piece. This picture will seem conservative to some—but it is worth reiterating that we will develop intelligences greater than our own, and it will radically change almost all aspects of our lives, our analysis is limited to the near-term economic picture.
There are a few variables across this whole analysis for which different assumptions would produce very different technological and economic outcomes. The most obvious is what is the inference cost of running digital researchers and cognitive labourers—if it is cheap to run both, we should expect faster research progress and we should expect greater economic growth from normal sectors of the economy. We note that it is important not to have too much confidence in a specific vision of the future; but rather see the direction of travel.
The View From the Valley: The Economic Singularity Will Follow Superintelligence
In the dominant intellectual framework at the AI labs, artificial intelligence is the most important technology in the history of our species.8 The timeline looks something like this:
The Big Bang happened (13.8 billion years ago)
Planet Earth is formed (~4.6 billion years ago)
Mammalian life began (~225 million years ago)
Homo sapiens became the dominant species (~30,000 years ago)
Homo sapiens build a more intelligent mind than themselves (c. 2027)
The more intelligent mind builds superintelligence (a few years later)
It might generally be considered that humans alive right now are radically early—approximately 108 billion humans have ever lived, but if we expand to other planets, or run consciousnesses on computers, many more humans could live in the far future. For this reason, we live in the most important century that humans will ever live in. We live in a fragile world facing many existential risks — with an estimated a 1% chance of nuclear war every year, over 200 years the chance of a nuclear war is 86.6% — and creating superintelligence, while risking existential destruction too, offers a path out of this challenge. Trillions of humans can live, on other planets or simulated on computers, and all work can be completed by robots.
We are not intending to arbitrate this diagnosis. This belief structure is much like a religion—the superintelligence has been deified, existential risk is the flood, and the AI labs are our ark.
The New World will be created by an Intelligence Explosion. The anticipated narrative looks something like this:
The human researchers will make AI agents that are capable of performing AI research.
These AI agents are run at enormous scale (millions of instances!) making much faster research progress than human researchers were.
The AI system recursively improves itself to become a ‘superintelligence’.
These models greatly exceed human research capabilities and are able to make other technologies, and automate all tasks in the economy.
As a result, it is expected that all human labour (including scientific and technological progress), will be automated, and people will not need to work. We will live in ‘post-scarcity’—a state of complete material abundance. As an indicator of this sentiment, Roon, a pseudonymous OpenAI researcher on X, has tweeted:
“the future of work” there is no future of work. we are going to systematically remove the burden of the world from atlas’ shoulders
Part of this idea is that economic transformation will happen quickly—once 100% of tasks are automatable, this report from Open Philanthropy puts a one third probability of economic growth exceeding 30% per year, and this paper from researchers at Epoch AI say these levels of growth are ‘about as likely as not’. These views are based on idea-based growth models (exogenous) and researcher-based growth models (semi-endogenous or endogenous) which show explosive growth when AIs can substitute for humans in all economic functions.
Even without the automation of AI research, automation of a large fraction of cognitive tasks and scientific progress could lead us to explosive levels of economic growth. While lab leaders have not commented directly on economic growth, Dario Amodei (the CEO of Anthropic) has written that:
“[M]y basic prediction is that AI-enabled biology and medicine will allow us to compress the progress that human biologists would have achieved over the next 50-100 years into 5-10 years. I’ll refer to this as the ‘compressed 21st century’: the idea that after powerful AI is developed, we will in a few years make all the progress in biology and medicine that we would have made in the whole 21st century…[I expect] the human economy may continue to make sense even a little past the point where we reach ‘a country of geniuses in a datacenter’. However, I do think in the long run AI will become so broadly effective and so cheap that this will no longer apply. At that point our current economic setup will no longer make sense, and there will be a need for a broader societal conversation about how the economy should be organized.” [emphasis ours]
Meanwhile, Sam Altman expressed similar sentiments:
“The technological progress we make in the next 100 years will be far larger than all we’ve made since we first controlled fire and invented the wheel.…AI will lower the cost of goods and services, because labor is the driving cost at many levels of the supply chain. If robots can build a house on land you already own from natural resources mined and refined onsite, using solar power, the cost of building that house is close to the cost to rent the robots. And if those robots are made by other robots, the cost to rent them will be much less than it was when humans made them.…Imagine a world where, for decades, everything–housing, education, food, clothing, etc.–became half as expensive every two years.” [emphasis ours]
Do not dismiss these beliefs on the grounds they are shaped rather like a religion.9 If nothing else, it is vitally important to understand, and take seriously, the actions of those who are building this technology. It is trivially easy to find put downs that allow one to explain away the prospect of enormous change — stories of self-importance or commercial incentive. It is much more difficult, though worthwhile, to understand the AI labs on their own terms.
Getting automation to impact growth is harder than it seems.
This section is intended to provide a brief introduction to economic theory of how automation comes to increase productivity and growth. These mental models will be used throughout sections on AI research, R&D, and cognitive labour.
In 1870, the average American worker laboured for 60-70 hours per week. Today, the average is 35 hours. We can work fewer hours to buy many more goods and services, and much better things, because workers are much more productive per hour. Tractors mean the same amount of grain can be produced by fewer farmers. And almost all long-run growth (the pie getting bigger) ultimately derives from increasing productivity.
Technology boosts productivity in two ways. First, by making tasks “cheaper” in human effort, time, or material resources; and second, by creating new tasks.
When economists talk about automation, they talk in terms of tasks, not jobs. Take accounting: what an accountant is doing was changed a lot, first by early computers, which could run by calculations, and then by spreadsheet software, and more recently, by ‘vertical SaaS’ to help enterprises do bookkeeping. Sometimes this leads to a reduction in the number of people doing a job—there’s only so much accounting that a fixed number of businesses want to buy. But in other cases, the introduction of ATMs — which automates the task of giving out cash — actually led to an increase in the total number of bank tellers, as it increased the profitability of opening new branches.10 In other cases, all the tasks in a job have been completely automated, for example, lighting streetlights became unnecessary after electric street lighting was introduced.
When a task is automated, this increases productivity in two ways. First, because the tasks are cheaper, we have more resources to spend on the rest of the process, or elsewhere. Second, when one method of production gets cheaper, we tend to do more of it relative to other tasks within the same process.11 Exactly how much more we do depends on the similarity of the tasks. For example, taxis and the tube are close substitutes—if self-driving cars make getting a taxi cheaper, we should be happy because a) we’re spending less on transport, and b) because we’re using taxis in situations we otherwise wouldn’t have done because they were previously too expensive.
Where the additional resources flow to increase production depends on whether tasks are substitutes or complements. If one task is automated—say, cotton weaving—the complement to this task—for example, printing designs on cotton—becomes more valuable as a result. On the contrary, when cotton weaving was automated, the substitutes to this—handweaving—became less valuable. When a task in the production process gets automated, if the remaining tasks are very strong complements, output might not rise by much at all. For example, if there is a packaging machine for cotton goods which is already operating at its limit, the automation of weaving will save resources, but cannot increase the output of cotton goods.
The same pattern applies at the level of the economy too! If there is more extensive automation in some sectors, the price of goods produced in that sector will fall, and so that sectors’ share of GDP (total output) grows less. This means that GDP ends up being composed of things which are essential, and yet hard to automate. Agriculture used to be 90% of GDP, but since mechanisation, it has shrunk as a fraction of GDP, to just 0.8%. Total output is bottlenecked by that which is essential — healthcare, education, housing — but hard to automate! This is known as the Baumol effect.
The important things to keep in mind when considering any automation are: how much does this automation directly reduce costs, and to what extent is output bottlenecked by this, or another factor?
AI research will be automatable, but the practical details will matter a lot.
The stated goal of much AI research is to make an AI researcher. The hope is that by automating the work of human AI researchers, we can make faster progress in AI research. This is for two reasons:
Because we can run more copies of the AI researcher than we can have human researchers.
Because we can engineer the digital AI researcher to continue getting cleverer than the human researcher, in an essentially unbounded way.
What does progress towards the AI scientist look like?
To get the digital AI scientist, the system must be able to perform all the sub-tasks involved in AI research.
What does an AI researcher do?
From a series of interviews with AI researchers, Epoch AI created a taxonomy of the tasks involved in AI research. In the simplest model, AI researchers create hypotheses, design experiments, run the experiments, analyse the results, and repeat this cycle.

There are many valuable questions which could provide a clearer picture of what it would take, and what it means, to automate this:
How much time do AI researchers spend between hypothesis generation, designing experiments, and analysing results?
When AI researchers reflect on their own cognition while generating hypotheses, what kinds of reasoning are they doing?
How much time do they spend waiting for the results of experiments?
(I could go on…)
There are very few public resources which deal with automating AI research at frontier labs, but more specific materials would make predictions of transformative change much easier. For most of this analysis, we rest on an enormously valuable interview on the Dwarkesh Podcast with Sholto Douglas (a Google DeepMind researcher) and Trenton Bricken (an Anthropic researcher).
Current systems are getting better at ML engineering, but performance struggles over longer horizons…
How do state-of-the-art models perform on our current tests of AI R&D?
We develop tests of AI research, or benchmarks, which can give us a smooth function of how much progress we are making towards the capability. Good benchmarks give you a score out of 100 on a diverse range of tests that most closely mirrors the capability in the real world. There are three main benchmarks which test a model’s AI Research abilities13: OpenAI’s MLE-bench; METR’s (a non-profit model evaluator) RE-bench; and OpenAI’s SWE-bench Verified.
MLE-bench tests the models against 75 ML engineering questions from online competitions (Kaggle). The latest public scores on this benchmark are for o1-preview, which lags o1 and o3. O1-preview performed in the top 40% of humans who had completed these ML engineering tasks on 16.9% of occasions. We should expect o3 to perform significantly better on this benchmark.
RE-bench tests the models against seven ML engineering tasks relevant for frontier R&D.14 In the evaluation, o–1 preview and Claude 3.5 Sonnet outperformed human experts with a two-hour time budget, but model performance asymptotes while human performance continues to rise with additional hours.
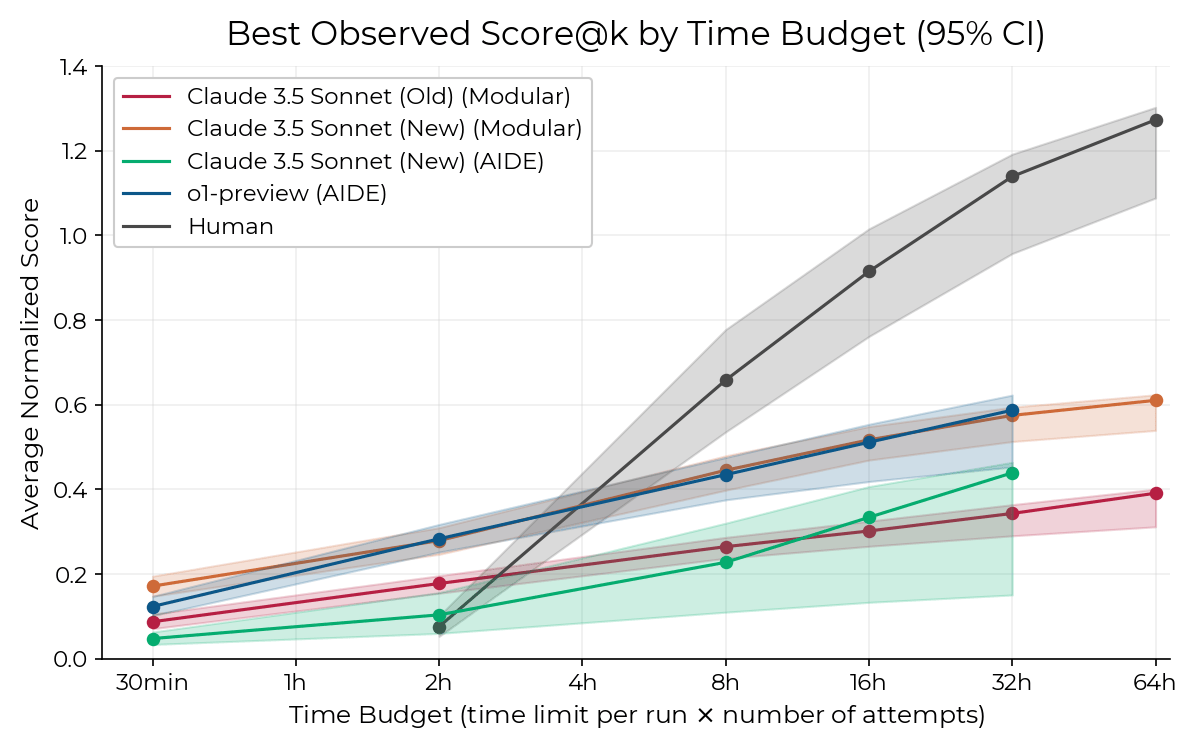
It is noteworthy that, on the task of optimising a kernel for latency, one of the models was able to find a solution with lower latency than the best solution from any human researcher in the benchmarking.16 As with MLE-bench, we expect that o3 performs significantly better than o1-preview. To provide an indicator to the trajectory of progress, Sholto Douglas tweeted that within six months, they expect state-of-the-art models to outperform human researchers with a time-budget of four hours.
SWE-bench verified tests model performance on real-world software engineering tasks. These do not reflect the models’ ability to do ML research, but provide a more general indicator of their coding ability. OpenAI’s o3 release in December 2024 took state-of-the-art performance to 71.7%. We predict this benchmark will be saturated (i.e. so close to 100% that it no longer useful distinguishes between models) in 3 to 6 months.
Finally, it is notable that ARC-AGI-PUB—a benchmark of models’ visual reasoning abilities—has become saturated. It measures performance on a series of visual reasoning puzzles (a bit like non-verbal reasoning tests, for those who went to school in the UK). The AI models have historically struggled with these problems, but humans would find them trivially easy to solve. GPT-4o, released in May 2024, scored just 5% on the benchmark; o1-preview scored 13.3%, but now, o3 is able to score 88%.
At this point, it is useful to reflect on what it would mean for all these benchmarks to become saturated. These are necessarily imperfect snapshots of what it is to do AI research. These tasks do not map comprehensively to Epoch AI’s taxonomy above. As one of the creators of RE-bench notes, their benchmark does not capture the models’ ability to interact with large and messy codebases, and make compute allocation decisions. However, these benchmarks provide a guide for the rate at which models are becoming better at ML engineering.
Improving these capabilities technically will depend on training systems for better long-horizon task performance. For more detailed coverage, see these pieces in Inference.
Partial automation is unlikely to provide much productivity uplift to AI research.
As we have mentioned earlier, the relevant question to consider for automation is: how much does automating this step actually impact output?
In this case, we want to know how much research output is increased by an agent (“the proto-AI researcher”) which is:
Less good than human researchers at generating hypotheses;
But can do software or machine learning engineering faster than humans, at or above the level of human research engineers.
And it can create visualisations of research results with preliminary analysis, to present to human researchers.
We do not expect this “proto-AI researcher” to increase output much for the following reasons.
We strongly expect that the output of AI research labs is bottlenecked by compute. In the Dwarkesh interview, Sholto Douglas has said, “I think the Gemini program would probably be maybe five times faster with 10 times more compute or something like that.” It is notable also that, according to Situational Awareness (as of May 2024), “GDM is rumoured to have way more experimental compute than OpenAI”. Perhaps the returns to marginal experimental compute are even more dramatic at other AI labs.
But there is a more simple ‘outside view’ argument, for why we should expect AI research labs to be compute bottlenecked. Put yourself in the shoes of a Chief Scientist—if you aren’t saturating your experimental compute, you should be trying extremely hard to!
Maintaining experimental compute clusters cost the AI labs billions of dollars. In comparison, AI researcher salaries are just a few hundred thousand, to a few million dollars a year. If your researchers don’t have enough ideas to saturate the compute you have, you should hire more researchers! If your best researchers have too many ideas without the time to implement them, you should hire more research engineers to help them do this! Being in a regime where you aren’t constrained by compute means the bottleneck is something else, which are worse problems to have.17
Using the proto-AI researcher for implementing experiments would require researchers to change their workflows, which could limit, or even reduce, their research output. Researchers have spent their entire working lives honing their research process, and experimental design is hard. If their AI lab asked their researchers to switch to a new workflow for implementing experiments where they have to pre-specify their view of how to do an experiment, in natural language, this could dampen their creativity, or they could spend time correcting models which did not implement the experiment as well as they would have. For some researchers, writing the experiment is thinking about the experiment. Breaking up this flow could limit, or even negate, the benefits of faster implementation.
However, this view of limited progress could be wrong for a few reasons.
The proto-AI researcher could partially automate benchmark creation. It might sound weird to outsiders, but one of the places where AI labs are most bottlenecked right now is after an experiment, how do they work out if the change they made actually improved the model? They use benchmarks, like the ones we’ve already discussed, but finding good tests has been getting increasingly hard. Zhengdong Wang, a Google DeepMind researcher, has an excellent section in his excellent end of year letter, on the problem of working on a poorly specified goal like ‘make this model generally intelligent’:
But how does [the researcher] know which experiment is better? In the past, evaluation was easy because the desired result was clear. If one model won more games of chess, or predicted a protein structure with higher accuracy, then it was better. Today, “better” is vaguer and slower to get than ever before. Our researcher can interact with a model for a long time, or look at which model users like more when he deploys it. But to do effective research, he needs fast (read: automated) evaluations. So he resorts to a test or benchmark (colloquially, an “eval”) that is unambiguous enough, fast enough, and a good enough approximation of what he means by “better.” Concretely, sipping his coffee, our researcher is looking at a plot where training progress is on the x-axis, and performance on a test is on the y-axis. He wants performance to go up as training progresses.
…
In fact, you might even say that the only time AI researchers are doing AI research is when they choose the evaluation. The rest of the time, they’re just optimizing a number.
This matches with a lot of what we’ve heard from people at the labs—the multiple choice questions it is possible to generate are being saturated, and from here, we will need benchmarks of longer-horizon tasks. These benchmarks will need to provide agents with an environment to act in, a well-defined task that provides a signal of their intelligence, with a smooth function that summarises how well they are performing. (To think about how difficult this is, work backwards: what test can you design to show “this model is 50% ‘good at science’”?) From conversations with people who make benchmarks, they expect it could be possible to automate quite a lot of their work—setting up environments, designing verification tasks for the models, and orchestrating agents at scale. However, they also stressed there are compute constraints on running large-scale long-horizon benchmark tasks, and that models will need even harder tests, automating which might jump ahead of current model capabilities.
In short, if the researchers were able to get clearer and deeper signal about how their models are improving in the domains they care about, as quickly as possible, it could well accelerate iteration speed on the incremental improvements to the models.
The human researchers could be ‘freed up’ to spend more time on other tasks, like thinking about better experiments to run, or reading more literature which could sow the seeds for better ideas in the future, or think more deeply about their experimental results and what might be happening inside the models.
However, we are skeptical, because we suspect that actually writing experiments is a small fraction of the job. Sholto notes,
“People have long lists of ideas that they want to try. Not every idea that you think should work, will work. Trying to understand why that is is quite difficult and working out what exactly you need to do to interrogate it. So a lot of it is introspection about what's going on. It's not pumping out thousands and thousands and thousands of lines of code.”
If implementing ideas for experiments is only a small fraction of time to begin with, speeding this process up doesn’t create much additional time for more thinking about experiments to run.
Complete automation could be bottlenecked by ideation and research taste.
In models of automation, there are a small number of tasks which are the last to be automated. These are known as ‘holdout tasks’. Whether there will be holdout tasks, what these will be, and how long they might hold out for, are important for understanding the output of ‘proto-AI researchers’.
Longer explanations of technical progress have been covered here and here in Inference, but in the briefest manner: the systems which AI labs are training will be trained to perform long-horizon tasks. This requires improving the models’ ability to maintain goal-directedness and coherence (and not to drift off track, as is sometimes observed in weaker models). This also requires error detection and recovery, as weaker models typically get stuck in loops, making the same mistake. As part of this regime, the models are being trained to think for longer, in order to improve their reasoning and planning capabilities.
We are currently in an ‘inference-time compute’ overhang, which means we have the capacity to increase the amount of compute which AI systems are using during inference, for greater capabilities. The relevant question, for our purposes on the complete automation of AI research; is where does the overhang end?
It could be the case that we have all the relevant components of creating an AI researcher within this current overhang. Perhaps all that it takes to make AI researchers with better ideas than human researchers is to scale up the models’ ability to think for a long time, and give them good examples of human researchers research ideas for a given set of evidence. On the other hand, there could be some cognitive tasks which the current overhang is unable to capture, and so output remains bottlenecked by these. For example, perhaps the lead researchers who set the research direction of the lab, and have to set plans for an extended period are engaging in a type of reasoning which is inaccessible; or perhaps the digital AI researchers are unable to reach the reliability at generating good ideas of human researchers.
For the view that it is possible within the paradigm; see ‘AGI is an engineering problem’.
It is unlikely there will be a discreet moment when we ‘have’ the AI researcher. We expect it to emerge over time.
When the models’ ideas for experiments are 90%-as-good-as the best human researchers’, they will be used 0% of the time. But once the models’ ideas can sometimes generate ideas 105%-as-good-as the best human researchers’, the human researcher should notice and implement them. Despite this, knowing in practice when the model’s ideas are better than a researchers’ seems to be particularly difficult. AI labs could not gamble on automating AI research prematurely, only to discover their agents’ ideas are worse than human researchers at a competing AI lab. Discovering the models are better at thinking of ideas is likely to be a gradual process—when their ideas are roughly as good as the best researchers', deciding which side of the distribution around 100% they fall will be very difficult for the researchers.
To what extent can AI labs maintain an experimental compute budget?
Experimental compute is central to our narrative. If it can have such dramatic effects on research output — that 10 times more compute means 5 times more progress — then sustaining as much compute as possible is vital for all research labs. Whoever has the most compute might even be the decisive factor, for who reaches the AI researcher first.
In the headline there are enormous $ figures for big tech companies spending on AI infrastructure — just last week, Microsoft announced that it would spend $80 billion on building new datacentres in 2025 — but most of this will be to run inference for customers through their product suite or cloud, and not for experimental or training compute for AGI labs.
The economics of compute for R&D are different from the economics of serving models to customers.
When GPUs are used for serving customers, the goal is to generate as much surplus as possible. Because GPUs are very expensive — electricity is only ~10-15% of the total cost of ownership — you do not want them to be idle. If you want to have the biggest surplus, you'll need to run a) as many GPUs as possible, at b) as high utilisation as possible, whilst c) providing all customers with a suitable level of interactivity. This is extremely difficult — how do you split the model across multiple GPUs to tradeoff throughput and interactivity? How do you forecast the number of GPUs you'll want in 4 years' time (the horizon for making AI infrastructure decisions)? How do you know the kind of hardware you will need to run the models of 2028? To what extent will we make inference efficiency gains, so that demand for inference can be satisfied with a much smaller number of GPUs than it would take today?
On the other hand, R&D compute is about spending the surplus. The goal of R&D is to create new models, which will maximise your future surplus:
Either because the models are more widely useful, and so you can sell more tokens;
Or because they are differentially capable, so you can charge more relative to the cost of inference;
Or because they are more efficient to run for a given capability level, so you take more home as surplus.
If R&D compute is about spending the surplus you’ve generated, then your total R&D compute needs to be amortised over all your inference.
The total amount which needs to be amortised is rising over time. The table below from the Institute for Progress shows the growth in training compute over time. The computational power dedicated to the largest training runs will be 100 times as large in 2030, as in 2026. (Note that while pre-training scaling laws might well be slowing, more compute can be applied during post training. SemiAnalysis predicts post-training FLOP will exceed pre-training FLOP in future.)

The total cost of ownership for an H200 is roughly $10.5k per month.19 (edit: correction, this previously said H100, but should have said H200; the TCO of an H100 is ~$9k/p.m.) For a 100k cluster, the annual cost will be roughly $1.6 billion. For the median 2028 cluster, it will be roughly $8.9 billion annually for ownership (note this is not capex!). On top of this, add experimental compute. All algorithmic improvements need to be tried at multiple increments of scale, and so the training compute will need to be at least close to the largest cluster. We estimate, with low confidence, that all experimental compute, as well as for evals and for safety research might be the same as the training cluster. And so R&D compute in 2028 might be a $15 billion to $20 billion expense for the AI labs.
Paying for this means selling some tokens!
An important question to consider: what is the economically-useful life of a model? We will argue that…
The economically-useful life of a model is short.
‘Frontier’ capabilities seem to get commoditised quickly, which hurts margins. Thus far, OpenAI have generally released the most powerful capabilities first. But not long after, other AI labs have released similarly powerful models.
GPT-4 was released in March 2023, although it finished training in August 2022, and just four months after its release, Anthropic released Claude 2 and Meta released Llama 2. To what extent the capabilities of GPT-4 were commoditised at this point is debatable: Llama 3 had a markedly worse HumanEval score (a test of coding ability), but the point is that directionally, in just 4 months, the competitive differentiation of GPT-4 was diminished.
GPT-4 Turbo was released in November 2023, and by March 2024, Anthropic released Claude 3, xAI released Grok-1, and then in April, Meta released Llama 3. All of these models had roughly equivalent benchmark scores.
Finally, OpenAI released GPT-4o in May 2024; Anthropic followed in June with Claude 3.5 Sonnet, and Meta followed in July with Llama 3.1.
When the leading model is clearly differentiated, the AI lab who made it will be able to make excess profits; but when these capabilities are commoditised, their margin is competed away. The less margin there is, the more difficult it is to amortise the cost of training new models (and the more one depends on the size of one's customer base).
However, commoditisation of capabilities could end. In the previous paradigm, when there was only a single axis for improvement (base model scale) there was natural convergence towards similar levels of capabilities. In the new paradigm of inference-time scaling, the 'returns to ideas' rise—first, everyone needs to make the leap to follow OpenAI in being able to scalably apply more compute at inference time, and second, there are many different types of RL which could have this affect. If the labs are decorrelated in their approaches, it is plausible to imagine that their models could have more heterogeneous capabilities. Additionally, more advanced post-training techniques offer the potential for more advanced ‘personality’ elicitation from the systems: people generally seem to prefer Claude 3.5 Sonnet’s style, tone of voice, and writing ability over other models. On the other hand, even if the techniques labs choose are different, they will want to train their models towards the same tasks—being good at coding, being able to complete tasks on a computer—and so even with different research approaches, they can end up in the same place.
Irrespective of whether the software layer commoditises, hardware capabilities will take much longer to compete away.
Once Google DeepMind is able to unlock Chain of Thought models, we expect they will have strong cost advantages for running large models on TPUs, against others running on GPUs. The TPUv6’s operate in a pod of 256 other chips, while NVIDIA Hoppers, B100, and B200 are only able to maintain a pod of 8 chips. Even the next-generation GB200 only has a pod size of 72. Larger pods make more parallelism schemes possible (i.e. you can split the model across a wider number of TPUs, with more creative configurations).
(As a technical detail: CoT costs do not scale linearly, so as sequence lengths at inference get longer, the problem gets worse.)
Switching models is easy, which means margins are more competitive. Moving between model providers is as simple as editing a line of code to change the API call. From the conversations we’ve had, if your scaffolding is built correctly, changing the base model does not cause this to break. Perhaps this changes, as model providers build developer tools and add parts of the bundle to keep you in their system, but it is at least not true for now.
At present, there is no market for ‘non-frontier’ models. AI systems do not seem to have reached the efficient frontier of latency, cost or performance—there’s so much further to go. It also is worth mentioning that typically, how the smaller models with lower latency and cost are created is distilling the larger model (a la o1-mini is to o1) rather than having a different training process, or 'falling off' the frontier.
Inference efficiency gains mean that prices per token fall, so R&D compute has to be amortised over a larger number of tokens.
Over the past two years, token prices for GPT-4 series models have collapsed by roughly 240x, per the chart from Elad Gil below. What is driving this? We would guess that it is not entirely inference optimisations. Perhaps in the early months of GPT-4, OpenAI had limited compute resources for serving models, so the high token prices were a form of rationing. However, this provides some directional indicator for the kinds of inference gains made over the period. Perhaps it is an extremely obvious point, but if token prices fall by 240 times, whilst margins hold constant, then making the same amount of revenue at the end of the period would require selling 240 tokens for every token you sold at the start of the period.
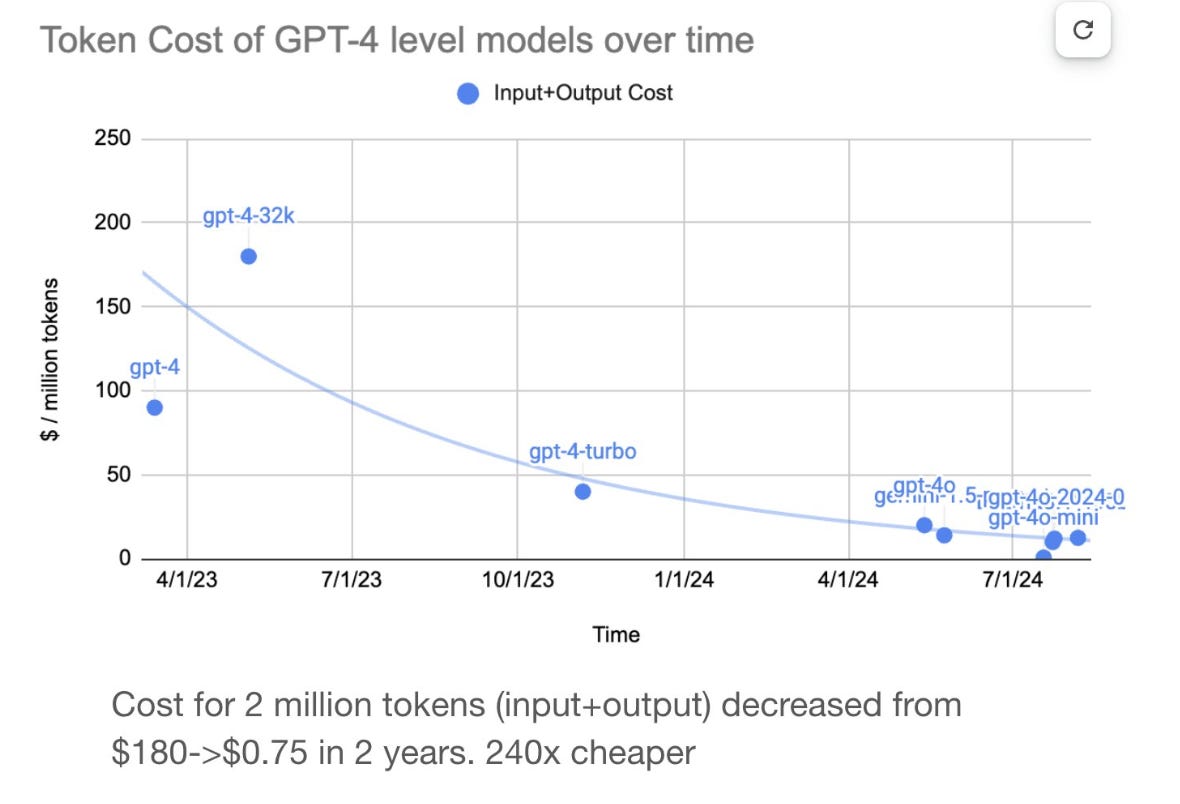
To step back from the analysis of inference costs, what these parameters have established in aggregate, is that each model has a window of opportunity to make a surplus that can be used to pay for R&D for future models. These windows seem to be short, with limited opportunity for margin throughout, and amortisation getting more difficult over time. Superintelligence seems like a bad business.
The labs will need to make products, not sell tokens, to fund R&D.
In order for this to work, AI labs need to get out of the token business, and start selling automated tasks or agents which can be priced in terms of their labour-equivalent.21 More on the impact of AI systems on cognitive labour in a later section.
Allocating the experimental compute budget is difficult.
Most visions of fast AI progress, in our opinion, assume away the problem of compute budgets. In practice, experimental compute is hard-won; and to what extent computational power can be dedicated towards particular goals determines a great deal about how quickly they are achieved.
The amount of experimental compute that AI labs have places limits on the size of their human AI researchers teams.
Even without the digital AI researcher, if an AI lab was going to hire the marginal human research, they would need to divide compute between ‘n + 1’ researchers. This means that some fraction of the compute from your best researchers will be reassigned to the new researcher. Because there are extremely high returns to research talent, and compounding benefits to intuition and research taste from having run lots of experiments; it is quite likely that it does not make sense to add more human researchers at all. In fact, labs might want to centralise lots of compute behind a very small number of very talented research scientists, and have the great majority of people improving their efficiency; a bit like a Megazord from Power Rangers. For an AI researcher to get involved in the research pipeline, their ideas have to surpass what the best researchers could otherwise spend the compute on.
Instances of the digital AI researcher will not be run on the cluster they were trained on.
The arguments for the Intelligence Explosion are premised on the idea that we will run the instances of the AI researcher on the cluster they were trained on. This does not seem to match how we’d imagine AI lab compute budgets work, nor how it would be optimal for them to work. For starters, where would the next model be trained? We would expect that the compute budget of an AI lab looks something like this: ~60% of compute on serving customers’ models; ~20% on training compute for the biggest run (~10% on pre-training, ~10% on post-training), ~10% on experimental compute, and ~10% on ‘other things’ (e.g. synthetic data generation, safety research, evaluations). Therefore, if the labs wants to run instances of the AI scientist, these will need to be traded off against experimental compute. The question then becomes: what is the marginal use of this compute? The next-best experiments of the best human researchers, or instances of the AI scientist to think about what experiments to run?
In this view, the digital AI researcher's ideas would need to generate much better ideas than those of the human researchers, otherwise it would not make sense to use up the compute.
The early inference costs of the AI scientist are likely to be very high, though we should expect them to fall dramatically.
The narratives for the Intelligence Explosion rely upon inference costs for the AI researcher being trivially low. Recent examples of Chain of Thought models have shown them using enormous amounts of inference compute—if it cost $3400 on average to solve each ARC-AGI benchmark prize, and we use the token prices of o1-preview, it took roughly 128,000 tokens to solve problems which are trivially easy for humans to solve.
A quick technical detail: recall that inference costs of CoT models do not scale linearly, as the model is forced to parallelise across multiple pods.
If we are to get additional capabilities through scaled Chain of Thought, this description of the AI researchers in Situational Awareness would seem to have astronomical inference costs…
“[T]hey’ll [each of the 100 million AI researcher] be able to get incredible ML intuition (having internalized the whole ML literature and every previous experiment every run!) and centuries-equivalent of thinking-time to figure out exactly the right experiment to run, configure it optimally, and get the maximum value of information; they’ll be able to spend centuries-equivalent of engineer-time before running even tiny experiments to avoid bugs and get them right on the first try; they can make tradeoffs to economize on compute by focusing on the biggest wins; and they’ll be able to try tons of smaller-scale experiments (and given effective compute scaleups by then, “smaller-scale” means being able to train 100,000 GPT-4-level models in a year to try architecture breakthroughs).”
It also seems to endow the AI researcher with an unfounded omnipotence. One way to describe GPT-3 is “imagine a model trained by reading billions of words of internet text, and across books, and Wikipedia; it will have superhuman intuitions about all kinds of different topics”, though this is clearly incorrect. The GPT-3 learning algorithm clearly isn’t that sample efficient nor is the degree of generalisation as-good as this would imply. Superhuman AI researchers will certainly exist in the future, but to assume these early generations will have this kind of power seems to imply extremely radical improvements to the learning algorithm which do not strike us as easily gained.
The productivity impact of the AI scientist could be capped, if the job of an AI researcher is to make ‘shot calls’ about which experiments need more compute.
One of the challenges of AI research is that experiments at different increments of scale can show very different performance. We’ve had RNNs, CNNs, and LSTMs (different neural network architectures for decades) but we’ve only have the computing power since the late 2000’s / early 2010s to be able to make use of them. In the episode of the Dwarkesh Podcast earlier cited, Sholto comments:
“[Y]ou never actually know if the trend will hold. For certain architectures the trend has held really well. And for certain changes, it's held really well. But that isn't always the case. And things which can help at smaller scales can actually hurt at larger scales. You have to make guesses based on what the trend lines look like and based on your intuitive feeling of what’s actually something that's going to matter, particularly for those which help with the small scale.”
One way to think about what this does to your comment budget is that it divides it into a convergent series (or put another way, a series of Russian Dolls), up to the largest training run. We can do many small-scale experiments, increasing the scale until reaching the largest (and longest) training run. From the episode;
“Many people have a long list of ideas that they want to try, but paring that down and shot calling, under very imperfect information, what are the right ideas to explore further is really hard.”
The biggest decisions the labs will make are ‘shot-calling’ about what goes into the largest scales. I think there are two important questions here:
To what extent are the potential gains to better decision making here capped?
To what extent are there marginal returns to intelligence for ‘shot calling’?
It seems to us that some of the world’s smartest people, with decades of AI research experience making these calls; and it seems doubtful as to how much more correctly it is possible to make these decisions. We could be quite close to the limits of possible correctness in this task, for which marginal intelligence would not assist much.
However, AI progress could go much more quickly than our picture suggests, if the digital AI scientists are much better at predicting the results of experiments than human researchers, or run at very low inference costs.
Being able to predict the results of an experiment—what in humans we might summarise as ‘intuition’—is immune to compute bottlenecks. If the digital AI researchers are able to get superhuman intuition about which experiments to run, and which aren’t worth running, it could make the total research output rise dramatically, even whilst experimental throughput remains constant.
Furthermore, making a big inference efficiency improvement could dramatically improve the usefulness of AI researchers—a 50% gain would either mean the same ‘population’ can run on half as much compute, with the other half going to experiments, or it is possible to run double the number of AI researchers. We’ve heard conflicting stories about whether this is possible. Some people have suggested that we’ve reached a ‘global minimum for inference costs’, as we will scale Chain of Thought reasoning faster than it is possible to make inference efficiency gains. On the contrary, others have been relatively optimistic about our capacity to make inference gains.
How much can chip supply be scaled, if it needs to?
This depends on the time scale.
The principal consideration here is frontier fab capacity—the H100 is fabricated using TSMC’s specialised process for AI chips called 4P (confusingly at 5nm), and the soon-coming Blackwell chips will use the same.
At the moment, AI accelerators make up a small fraction of 5nm capacity. For an estimate of how much they use, from this FT article, Microsoft bought 485,000 Hoppers — we will assume all H100s for simplicity — in 2024; Meta bought 224,000; Amazon, 196,000; Google, 169,000 (though of course, Google also has TPUs); and although it isn’t included, let’s assume that x.ai bought 125k GPUs. This is just short of 1.2 million H100 GPUs last year. Using the die size and some reasonable assumptions for yield, we can estimate this would have required 16,000 to 20,000 wafers. This is approximately a mere 0.3-0.4% of TSMC’s annual capacity in 5nm and below.22
Remember this is not the complete picture of demand—roughly half of NVIDIAs revenue comes from the hyperscalers, the remaining half from neoclouds, startups, governments and so forth. Amazon, Microsoft, OpenAI are all developing their own custom silicon; and Google is on their 6th generation TPU. AMD is also making the MI325X to compete with NVIDIA’s next generation Blackwell. Furthermore, growth rates are high—NVIDIA’s most recent earnings reported revenue from their datacentre business (i.e. selling GPUs with all the extras to make them work) at $30.8 billion. A year earlier, this was $14.51 billion; and a year before that it was $2.94 billion. In their Q1 2024 earnings call, TSMC gave guidance that they expect their AI processor business to grow at 50% per year, and become more than 20% of their revenue by 2028.
The production of AI accelerators could use capacity at 3nm and 4nm, but prices would need to rise, to outbid 3nm and 4nm demand, as there are higher costs for TSMC at the leading-edge.
There are potential bottlenecks in advanced packaging (CoWoS packaging capacity is lower than demand until at least 2026) and in high-bandwidth memory, which limit scaling production in the next 1-2 years, though it is expected these bottlenecks will alleviate.
Building a leading-edge fab (chip factory) takes three to five years, though TSMC’s Arizona facility is delayed until 2027 or 2028 (construction began in December 2022) reportedly due to a combination of low demand and uncertainty regarding US subsidies.
So, in short, there is a lot of room to grow within the existing fab capacity, though for the next couple of years this is limited by HBM and advanced packaging capacity. New fab construction requires significant capital expenditure, and therefore certainty of demand. New fabs could be commissioned to meet AI-related demand in future, but current projected demand in the 2020s remains far off this being the case.
We think the capacity to scale chip production is one of the most important inputs into the rate of progress, and so we will be dedicating a full piece to it, in the next edition of Inference.
Expect big improvements in human welfare from AI automating science, but don’t expect that these gains will come quickly.
Most of the improvements to human wellbeing in ‘frontier’ economies comes from making scientific discoveries and turning these into new technologies. When AI lab leaders speak about the opportunity of AI, it is principally the scientific opportunity which they see as most exciting. Our scientific ambitions for AI should be enormous: ending disease, extending life, making abundant clean energy, more performant and green materials, ending unpleasant labour through robotic automation. We will also come to better understand human minds, wellbeing, and the most fundamental scientific questions. Like with AI research, automating R&D depends on automating hypothesis generation, experimental design and implementation, and data analysis. Also like AI research, experimental throughput constraints scientific progress.
Current AI systems can improve human researchers’ hypothesis generation.
The literature review process can be greatly enhanced with AI. FutureHouse, a non-profit research organisation, has built PaperQA2, a literature review agent. Against a test of questions, where the answer was to be found only in the body of a single scientific paper, this agent was able to correctly answer 60.3% of questions. It was able to write cited, Wikipedia-style summaries which experts ranked as more accurate than the existing human-written Wikipedia articles in some scientific domains. It is notable that this agent was released in September 2024, before o1 or o3 were released, which will perform much better on GPQA (a benchmark of scientific expertise). It seems reasonable to imagine that by the middle of 2025, it will be possible for AI systems to write a literature review to postgrad-level.
Another example of the possibilities comes from Professor Derya Unutmaz, at the Jackson Laboratory, who studies cancer immunotherapy who prompted the model to support with experimental design, and subsequently wrote:
"While o1-Preview and GPT-4o were able to generate some interesting ideas based on this concept, but they were mostly what I could also conceive though better [than] most PhD students. In contrast, o1-Pro came up with far more creative and innovative solutions that left me in awe!"
Here is the full output.
As an aside, language models can easily automate grant applications. This is quite a trivial use for AI systems now, clearly not using the frontier of their capabilities—but the Faculty Workload Survey of 2018 from the USFDP which received responses from 11,167 Principal Investigators said administrative requirements took 44.3% of their time. If we automated grant applications, would scientific output double as a result of the saved time? On the other hand, decreasing the cost of information processing might lead scientific funding institutions to impose greater reporting requirements, eating away any potential gains.23
Notably, all of these automations are pretty easy! They do not require large capital expenditures and scientists can choose to integrate these tools ‘bottom up’, as 1/3rd of postdocs already have.
Academia is poorly configured to adopt AI.
Because automation will happen lab-by-lab, there are low returns to scale.
Because academic salaries are lower than other equivalent levels of labour skill, there are weaker incentives to automate.
There are high capital costs to robotic lab automation, for which the returns are uncertain.
Incentive mechanisms in academia, for example, towards grant funding for longer periods, and positions being tied to projects, could make it harder to pivot research to focus on new capabilities.
However, we can create new AI-first scientific institutions through structures like FutureHouse, Convergent Research’s FRO, or ARIA. One parallel to think about this is how electricity improved productivity, not just in electrifying processes, but in making the assembly line possible—in what ways might we completely reorganize the institutions of science (perhaps around models, datasets, or experimental automation) that allows us to capture the full upside? Perhaps these things have to be reimagined from the ground up.
Scientific automation faces many intrinsic headwinds.
Most sciences require ‘real world’ experiments whereas AI research only needs experiments within the computer. It is possible that progress in AI research will result in improvements to improve our simulations—of the cell, of particle physics, and so forth; that can partially substitute for experimentation, but there will be limits to this.
There is no ‘programming language’ for recording experimental design, in the same way that in AI research the experiments are recorded exactly as they were implemented in computer memory. This means that training agents to do AI research is much easier, because the AI labs will have a very rich corpus of data on which to train, whereas for agents to plan biomedical researcher experiments, we lack such a corpus and instead train on non-standardised descriptions of methods in academic papers.
A very small fraction of the total data which research labs could collect, is collected. Organising data collection otherwise would impose big constraints on the scientists’ productivity. On the contrary, computers capture AI research by design
This property of experimental research means that AI labs will have a corpus of negative results that would never be published, whereas in biomedical sciences, these are not published and are unlikely to be recorded in a structured format.
Chip R&D is especially susceptible to these challenges described.
The processes for chip production, as well as for R&D are highly secretive. Only TSMC will be able to automate what they do directly.
Knowledge about how to do chip research is often tacit and master-apprentice.
The complexity is so incredibly high—there are so many steps in the process, many of them are multivariate problems, and nobody has good visibility of the process.
As mentioned above, lots of chip research requires large amounts of real-world experimental throughput.
However, this argument could be incorrect in a couple of important ways.
First, there are some steps in the chip R&D process which have enormous leverage over other steps. Ultimately a large fraction of the performance improvement comes down to whether it is possible to shrink the node size—between Hopper and Blackwell it wasn’t, and quite a lot of the additional performance of Blackwell comes from how it was possible to make the chip bigger. (Granted this is still an important jump forward!)
DeepMind have developed AlphaChip, which has partially automated aspects of chip floorplanning (arranging where components go on the chip). This has reduced the wirelength, important for communication speed, on the TPUv6 by 6.2%; but is somewhat bounded in its capacity to produce more computing power. The important question to ask about the chip process is: where are the marginal returns to intelligence very high?
Second, there can be unintuitive substitutes in R&D. If you had asked us to explain why the discovery of protein structure does not get automated in 2014, we would plausibly explained the difficulty of automating the process of x-ray crystallography — it’s hard to do the purification, to grow the crystals and so forth. Of course, we would have been wrong! Not in the direct sense that getting robots to x ray-crystallography would be easy, but that it turned out with a sufficiently large dataset of previous examples of x-ray crystallography and some hard-coded understanding of bond angles, we can create an AI system — AlphaFold — which is able to completely bypass this. Perhaps extremely intelligent systems will be able to spot much more difficult ‘bypasses’ and take advantage of them.
Biomedical advances will be bottlenecked by experimental throughput, and social welfare improvements will be bottlenecked by regulatory approval.
Dario Amodei’s essay, Machines of Loving Grace, details the changes which he thinks could arise from ‘powerful AI’, the model which results from some period (in his view, near), after the AI scientist where we have ‘a country of geniuses in a datacentre’. This model can control lab robots or tell humans which experiments to run. He thinks that we might be able to increase the speed of biomedical research progress by 10 times, which would mean in 5 to 10 years, we can make progress like:
Reliable prevention and treatment of all infectious diseases
Elimination of most cancer
Very effective prevention and effective cures for genetic disease.
Prevention of Alzheimer’s
Improved treatments for most other ailments (diabetes, heart disease, autoimmune diseases and more.
Biological freedom (improvement to birth control, fertility, management of weight etc)
Doubling of the human life span through therapeutics.
What would it take to increase experimental throughput by a factor of 10?
There are roughly 146,000 medical scientists employed in the United States. This would mean that 1.4 million people would be needed (or perhaps slightly fewer, as perhaps the job is more focused on experiments) to increase our throughput by a factor of 10, if the quality of experimental ideas is held constant. These people would need new buildings to work in, which typically take a year or two to build; and there would be many other things that have to happen like training the scientists at least in basic procedures, in order to get this scale-up.
On the other hand, we might not need a direct ten times increase in experimental throughout, perhaps if the models improve the quality of our ideas and the data we’re able to generate from each experiment, we need fewer experiments, so fewer buildings and so forth.
There is also the question of regulatory approval for new therapeutics. In this regard, Dario is also optimistic. He writes:
Although there is a lot of bureaucracy and slowdown associated with them, the truth is that a lot (though by no means all!) of their slowness ultimately derives from the need to rigorously evaluate drugs that barely work or ambiguously work. This is sadly true of most therapies today: the average cancer drug increases survival by a few months while having significant side effects that need to be carefully measured (there’s a similar story for Alzheimer’s drugs). This leads to huge studies (in order to achieve statistical power) and difficult tradeoffs which regulatory agencies generally aren’t great at making, again because of bureaucracy and the complexity of competing interests.
When something works really well, it goes much faster: there’s an accelerated approval track and the ease of approval is much greater when effect sizes are larger. mRNA vaccines for COVID were approved in 9 months—much faster than the usual pace. That said, even under these conditions clinical trials are still too slow—mRNA vaccines arguably should have been approved in ~2 months. But these kinds of delays (~1 year end-to-end for a drug) combined with massive parallelization and the need for some but not too much iteration (“a few tries”) are very compatible with radical transformation in 5-10 years. Even more optimistically, it is possible that AI-enabled biological science will reduce the need for iteration in clinical trials by developing better animal and cell experimental models (or even simulations) that are more accurate in predicting what will happen in humans. This will be particularly important in developing drugs against the aging process, which plays out over decades and where we need a faster iteration loop.
We believe this understates the extent to which getting drugs through the regulatory approval process is bottlenecked by more capable systems. Semaglutide seems like the kind of magnitude of discovery we would hope that AI systems are able to produce for us, but the patents were first filed in 2008, and only within the last 5 years have we begun to see its scale up. Similarly, the Malaria vaccine needed 23 years in clinical trials.
Getting regulatory approval bodies to use AI systems for therapeutic approval seems difficult, and unlikely. Their incentives are towards risk-avoidance, they would need to trust the evaluations from the simulations, and re-configure their processes in order to integrate these systems. (It seems more likely that a new, parallel regulatory agency would be set up to have AI analysis capabilities built natively into their approval process.) Additionally, this change would require the public to trust new methods of approval.
Robotics progress will be accelerated by the automated AI researcher. However, we are sceptical of the most aggressive models of robotics deployment.
Without making progress in robotics, the AI systems remain stuck on computers. There’s still a lot of leverage for systems which aren’t physically embodied, as we will discuss, there are a large number of tasks which can be done ‘remotely’. However, without making progress in robotics, further growth would become bottlenecked on manual labour from humans—it would be a Baumol effect. The cost of information processing would fall, and so physical tasks would rise as a relative fraction of the economy.
Robotics progress is bottlenecked on data for them to learn how to act. OpenAI closed down their robotics work in 2021, in order to focus on language modelling, where there was a lot more data because of the Internet! (Note that OpenAI’s robotics team restarted a few days ago.) With the digital AI researcher, there will be two advantages to robotics progress: first, progress in video modelling—improving upon OpenAI’s work on SORA and DeepMind’s work on Genie and veo—could provide much better simulations of the real world, to train the model. The AI researcher could apply general AI algorithm improvements from training better computer-based systems, and also make progress on breakthroughs in computer vision algorithms, specifically for the robots.
There are a number of related questions for how fast we might see general robotics make a larger contribution to the economy:
How readily can the digital AI researcher generalise to become a robotics researcher?
How quickly can algorithms for robots be improved, so as they can match human level performance?
How much of their training can happen in simulation instead of the real world?
How much prototyping and testing needs to happen on the hardware? How much of this testing can happen in simulation vs in the real world?
What are the holdout tasks — say, like getting a robotic hand to match human dexterity — which are going to prevent complete automation for some period?
How long do the holdout tasks hold out?
Where does manufacturing happen, to what extent does this require skilled humans for assembly? Can the number of humans with these skills be scaled, until the robots can handle their own assembly?
How much training data can robots provide for models, and how useful?
We will be dedicating a full piece to the robotics scale-up, as it seems to be one of the most important components of the growth story for the coming decades, meriting further investigation.
Cognitive labour will be automated before physical labour, and could be automated much more quickly than previous technological revolutions.
State-of-the-art AI systems have not made a very large GDP-level impact yet.24 This might seem bizarre—imagine going back to 2017 and showing someone the capabilities of OpenAI’s o3 model (very good software engineering, graduate-level scientist, and, from other models, near-perfect test scores in undergrad humanities). Surely one would have expected some noticeable increase to our collective output! It would be reasonable to have imagined big changes to ‘knowledge work’ already.
There are a number of factors that prevent AI systems performing tasks they are cognitively capable of doing.
Throughout this section, it is worthwhile to reflect on whether these constraints continue to be true as the models become more capable. In some cases, the challenges to deployment fall away as models get more capable.
Right now, implementing current AI systems requires building ‘scaffolding’ to improve reliability and performance. Most AI deployment in the real world has been workflows; where large language models and tools (like a code window, or internet access) are orchestrated through predefined code paths. These paths are known as scaffolding.
This happens because, until recently, language models have not been trained to perform tasks over time, just to predict the next token. To get them to do tasks, it would be necessary to stitch many prompts to the model together. Furthermore, businesses like deterministic processes. With scaffolding, the models are kept ‘on track’ and their performance improves.
Knowing how to build scaffoldings and deploy AI workflows is currently a rare, and valuable skill. However, we expect this to get much easier with greater intelligence. One way to think about the current situation is that the ‘intelligence’ is balanced between being inside the model’s parameters, and encoded in the ‘scaffolding’ of business logic. Over time, as the models get smarter, a greater share of the processing will happen inside the models and less needs to be encoded in the scaffolding. This will happen as the models are trained for agency, and other algorithmic improvements advance their ability to act in unfamiliar contexts.
Right now, interacting with the models feels like talking to someone who is very smart, but has no context at all. Over time, as their context length, and management of their context window and memory improves, the models will be able to understand environments (like the internal documents of a company, or a large codebase) much more easily.
In the limit, we should expect that orchestrating agents will be done by other agents. The final step of OpenAI’s AGI research agenda is ‘coordination’—getting different AI agents to work together on problems. As part of this, one agent will be able to create a smaller ‘sub-agent’ which could be specialised to a particular task.
Right now, implementing current AI systems requires businesses to reconfigure their processes. State-of-the-art models are capable in some domains, but they are ‘unbalanced’ and struggle at some tasks which are very easy for humans. Model deployers need to account for this, and engineer the scaffolding for workflows, to allow humans to complete tasks which models struggle with. As it has been put previously, ‘there are no AI-shaped holes lying around’.
Over time, the models will need less structure to fit into organisations. The AI labs will improve the interactivity of the models—it will be possible to interact through many modalities in a much more natural way, and proactivity will be trained into the models during agency training. This is the opposite of what happens when we interact with Chatbots—they are trying to say less, to save on generation costs!
However, in many contexts, the deployment of AI systems is bottlenecked by organisational politics, and not the capabilities of the models. Nabeel Qureshi has an excellent essay reflecting on his experience working at Palantir, in which he writes:
“[O]ften what really gets in the way is organizational politics: a team, or group, controls a key data source, the reason for their existence is that they are the gatekeepers to that data source, and they typically justify their existence in a corporation by being the gatekeepers of that data source (and, often, providing analyses of that data). This politics can be a formidable obstacle to overcome, and in some cases led to hilarious outcomes – you’d have a company buying an 8-12 week pilot, and we’d spend all 8-12 weeks just getting data access, and the final week scrambling to have something to demo.”
Current systems might speed up the final week of production, but don’t affect the first 11 weeks of this project!
As in this case, in some domains, customers will have a preference for interacting with a human. There is some preliminary evidence that o1-preview surpasses general practitioners on the reasoning aspects of diagnostics. The paper gave o1-preview summarised descriptions of symptoms in text boxes, and asked it to provide a diagnosis. Of course, this only captures a very small fraction of what it means to be a doctor! Doctors are performing a blend of tasks—asking questions to establish the symptoms, expressing care and empathy, tailoring their explanations to the patient so they can understand, and making diagnoses. While it is highly likely that AI systems will surpass human capabilities to make diagnoses, most people will retain a preference for experiencing healthcare in person rather than through an online interface.25 The tasks which make up the job will be changed, and the interpersonal factors will increase in relative importance.
Furthermore, labour organisations may to resist automation. This paper used semantic analysis of patent filings to predict where on the skill distribution we should expect AI systems to have the first impact. It predicts ‘upper-middle’ jobs, like being a doctor, lawyer, or software engineer will be most exposed to automation from AI. As Webb notes in this podcast interview, doctors and lawyers are likely to be able to lobby for regulations which require a human to remain ‘in the loop’ in places they could otherwise be automated. On the other hand, intersectoral mobility for jobs which typically happen in cities and in ‘knowledge work’ is typically easier than, say, adjustment for coal miners who lived in places where coal mining was the only industry. Furthermore, there are typically lower levels of labour organisation in ‘knowledge’ work, and so we should perhaps expect less coordinated action.
Both factors, the preference for human-produced services and labour organisations, could be diminished by more capable systems. In some domains, by far-and-away superhuman AI systems would incentivise people to switch from human-produced services (imagine AI produced films vs human-produced films) and would make it ever-more difficult for labour organisations to ignore the differences in performance between the systems (imagine noticing rare conditions earlier and more accurately than human doctors could ever manage). However, there are some places where human services augmented by AI will always be superior to just AI; and there will be some responses to automation that are difficult to predict (e.g. on the grounds of safety; autonomous cars currently have 90% fewer crashes than humans over a large sample of miles driven, but have not been deployed more widely). There is also an income effect from higher automation - increasing the demand for human interaction.
At present, humans need to be liable for AI systems. There is no legal framework (as yet!) to determine liability between model developers, ‘product’ companies (which fine tune models on proprietary data), and users of the models. But even if there was, models are not capable of acting unsupervised for long periods, they lack the error-correction, reasoning, and coherence to be reliable. Managing AI systems will become easier over time, as these capabilities are trained into the models, and so plausibly a single human can manage a larger team of agents as they need less frequent input from supervisors. We will also develop better infrastructure for escalating potential errors to AI and human oversight systems, to avoid mistakes. In the limit, AI agents will become capable of running entire firms in some industries; and humans will control a holding company for these firms, taking legal, but not managerial responsibility.
Regulation could prevent AI use and bottleneck deployment and productivity gains. We turn down technology currently, which has detrimental effects both on economic growth and social welfare. For example, this paper estimates that the slowdown in nuclear power construction since Chernobyl, in favour of fossil fuels, has cost 400,000 to 7 million lives globally. Nuclear could also provide electricity at prices competitive with solar, but due to a scientifically inaccurate approach to radiation exposure and poorly configured regulatory apparatus, it has been regulated to near-infeasibility.
However, AI might increase jurisdictional choice for businesses to operate, as they become less dependent on labour, and increasingly dependent on capital (datacentres, robots, robotic labs, factories etc). When this happens, it might cause regulatory approaches to soften, in order to capture some AI growth.
AI systems will be leveraged by humans, mostly not AIs running firms.
What should we expect AI automation to look like, concretely, in the near term?
The first AI agents to be released in the first few months of 2025 will be designed to complete simple tasks on your computer. Over time, these agents will become capable of performing a wider range of tasks on a computer, and acting for longer time-horizons. (For a more complete explanation, see ‘AGI is an engineering problem’ in this edition.) Anything which a human does just on a computer, an AI agent will straightforwardly be able to do in the next few years.
Coding agents will be especially important to track here. Mark Zuckerberg has said that:
“Probably in 2025, we at Meta, as well as the other companies that are basically working on this, are going to have an AI that can effectively be a sort of midlevel engineer that you have at your company that can write code.”
It is quite difficult to measure to what extent the actual productivity of software engineers is improved by this—lines of code does not mean more real-world output, as perhaps we bury ourselves in poorly designed software! However, it seems reasonable to imagine that software productivity could rise quite steeply.
We expect that knowledge workers will be managing groups of agents for computer-based tasks, using tools like Microsoft Copilot Studio, and over time, as the models’ capacity for long-horizon tasks improves, and their reasoning and planning capabilities advance further, the number of agents each human can manage will expand. We expect this to be like: “all humans are getting promoted”, at least in the near term.
Lots of knowledge work bundles cognitive capabilities with ‘embodied’ human skills, for example, product management, consulting, medical care, and law. We think humans will continue to do these jobs, because whilst the cognitive capabilities could be in-principle automated by AI; they are complemented by things which AIs will struggle to do, at least in the near term. Be charismatic, be empathetic, be ‘present’, be accountable. (Perhaps there is a vision for robotics whereby close mimicry of human emotion and embodiment is possible, though we exempt this from our analysis.)
There are a set of knowledge work professions which are not complemented by this kind of embodiment. For example, making good films, making software, and running a hedge fund. It is plausible that humans continue to do some aspect of this (telling the AI system what film to make, what program to write, or raising LP money for the AI running the hedge fund) though we think it is possible to automate these sectors entirely. If an AI hedge fund was likely to make better returns, you would invest with them, irrespective of the hedge fund sales.
We do not expect ‘AI composed firms’ to make up a majority of sectors.
Automating remote tasks could lead to rapid growth, but is very unlikely to lead to explosive growth.
We can build an economic model of tasks in the economy, and estimate which fraction of these can be automated, to predict how much AI causes growth to accelerate, under our assumptions mentioned above. There are three ingredients to any model of this:
What fraction of tasks are automated?
How well can these substitute for non-automated tasks?
How cheap are the AI systems that can substitute for human cognitive labour?
How much do Baumol and Engels effects make output growth concentrated in a small number of sectors less valuable?
Below we list our parameter estimates, if you would like to skip to our conclusions you can do so here.
What fraction of tasks are automated?
For the purposes of this, we are going to assume that all tasks which can be done on a laptop are automatable, and all tasks which require physical presence are not automatable in this model.
In the ordinary economy, there are a number of tasks which are not done ‘remotely’, but could be. Whilst most firms prefer their software engineers to be in the office, it is possible to do software engineering remotely.
The pandemic is a useful case study to understand, in the limit, how many jobs could be done remotely if they needed to. This survey suggests that 37% of jobs were done remotely during the pandemic. This is likely to be an overestimate for the number of jobs which are actually automatable, because when people were sent home for lockdown the question was not which jobs are suitably completed remotely, but rather, whether it is possible to get any output from workers who are stuck at home.
To adjust for this, we can break down by task instead of by job. Barnett 2025 uses GPT-4o to analyse ONET, the database of what workers in 1000 professions spend their time doing in the US economy; and finds that 34% of the tasks were automatable. This is quite different from 37% of jobs, because 34% of tasks can be spread across a wide range of workers in a way that could be bundled to affect production. For example, the scientist can write their grant proposal remotely, but if they cannot get access to the lab, their output will still be 0.
Estimating what fraction of tasks have an automatable (i.e. remote) component, bundled with an non-automatable (i.e. in person) component; is very difficult. To return to the earlier example of a Palantir engineer implementing a data platform, the cognitive task to figure out what product a company needs, is possible to do remotely, but it relies upon asking them questions to establish their needs, and building rapport—necessarily not automatable. To deal with this, and set a lower bound on the number of automatable tasks in the economy; we look at what fraction all of their top 5 tasks are remote. Barnett 2025 provides that this is 13%.
How well can automated tasks substitute for non-automated tasks?
Two reasons why task automation might be good
Spend less money on it.
Because it is possible to do that task more relative to another task, if it can substitute for it. (if you have better software, you can manage your inventory better, which means lower inventory, so lower trolleys for moving things around.)
We want to set a parameter (number between zero and infinity) which captures to what extent an automated task can do this substitution. How can we estimate this?
One of the ways Barnett 2025 estimates this is, again, by looking at the pandemic. At this point, there was a very large increase in the number of remote workers relative to in-person workers. This is an imperfect proxy for what happens when AI systems can be added to the economy quite easily (more remote workers). Total economic output didn’t decline very much—roughly 8%—which is surprisingly small, given that everyone was made to stay at home. This scenario produces an ‘elasticity of substitution’ (the parameter for how much an automated task can substitute for a non-automatable task) of 13.
This is extremely large! However, we don’t place much weight on this for a couple of reasons:
During the pandemic, roughly 1/3rd of US workers went remote. But, as we’ve already noted, 34% of tasks can be done from home. So all that has happened, roughly, is that these tasks have begun to happen from home. It does not, necessarily, tell us how well this 34% of tasks can substitute for the other 66% of tasks.
Remote work requires infrastructure. The pandemic prevents investment and maintenance from occurring. In the short run, this is not a big problem (it might even increase output); but in the long-run this problem becomes large. This can cause one to overstate the elasticity of substitution in the pandemic example.
What is another approach to estimating this? Very roughly, we can say that higher skilled workers tend to do cognitive tasks, and lower-skilled workers tend to do physical tasks. (We appreciate this loses a lot of individual difference, but we make a simplification for modelling purposes.) So it is instructive to see to what extent higher skilled workers can substitute for lower skilled workers. This provides an elasticity of 4.
What are some reasons to be suspicious of this? In order for things to have an elasticity greater than one, they need to be substitutes. Simply, what substitutes are, is when you can still produce something, if you only have one of them. We claim that high and low skilled workers are an example of this. High skilled workers can plausibly perform the tasks which lower skilled workers can perform. (We appreciate there will be exceptions, and the idea of ‘lower skill’ can be refuted, but again, this is a simplification for modelling purposes.) We would expect remote and in-person work to not be like this: if everyone was remote, then who would repair the factories, run the power stations, and care for the patients?26 This means high and low skill labour have to give an elasticity of substitution above 1, but this does not mean that remote and in-person work will have the same relationship.
Following Barnett 2025, we’ll use an elasticity of 0.5 as a lower bound.27
How cheap are the AI systems that can substitute for human cognitive labour?
We separately estimate the model at $4, $10, and $40/hour.
$10/hour is a very rough estimate of the cost for o1 tokens, generating for an hour; and $4/hour and $40/hour are ‘a bit above’ and ‘a bit below’. We recognise more precision could be useful here, and also note that this assumes inference costs remain roughly aligned with o1. There are a wide range of views about what will happen to inference costs in the future. As we argued earlier in the section on the slow rate of hardware commoditisation, Chain of Thought inference costs could well rise nonlinearly, although inference efficiency improvements will push in the opposite direction.
How much do more workers help growth?
Barnett 2025 assumes constant returns to scale in adding more workers—simply, twice as many workers leads to twice as much output, forever. The problem is that, in fact, workers need capital to produce things (e.g. machines, computer, tools etc to work with). If there are a lot more workers, without investing to raise the capital stock, the increases in output are determined by the elasticity of substitution between capital and labour. (Stepping back from the economics jargon,) we can either spend resources on adding a marginal remote worker—in this case an AI agent—or we can invest in more machines or tools—to make our existing AI agents (and humans) more productive—or we can spend those resources on consumption—the whole reason we’re doing this anyway!28
At this point, a sensible rebuttal could be, “Don’t labour and capital in this case both mean datacentre compute?” This would be correct in sectors which are completely automated, but we’re interested in what happens after this (these few sectors which are completely automated, by themselves, do not set off explosive growth). For example, doctors can benefit from more AI assistance interpreting scans, but if they want more scans, they’ll also need more MRI machines. Likewise, physicists can do many more simulations of experiments in a datacentre, but ultimately if they want to test them they’ll still need bigger particle accelerators.
Erdil & Besiroglu 2023 uses a literature review of estimates of the capital-labour elasticity of substitution, and this gives 0.45-0.87. However, in the literature review they cite, there is a distortion of the distribution of papers investigating capital-labour elasticity, whereby if people get a negative value, they do not publish their results. A negative value would mean that production would have been higher if there was less labour and less capital, and so people choose not to publish. In the graphs below, which show the distribution of capital-labour elasticities in the studies, there is a clear truncation of the left tail.

Therefore, the elasticity of labour-capital substitution is overestimated in Erdil & Besiroglu 2023. Gechert et al 2022 corrects this, and provides a capital-labour elasticity of 0.3.
This implies it is quite difficult to substitute labour for capital, and as such, even with a very large increase in workers, growth is bottlenecked by capital. This capital can be accumulated—although, due to imperfect insurance markets and finitely lived agents, potentially not fully. Getting through this will be slow and expensive.
What does this understanding imply for economic growth
We will now set out three cases for growth. Note that all figures are additional growth over whatever exogenous technological progress occurs.
The maximally optimistic case.
Elasticity of substitution = 4
% of tasks automatable = 35
Agents cost $4/hour
Realistic (upper bound)
Elasticity of substitution = 2
% of tasks automatable = 30
Agents cost $10/hour
Lower bound
Elasticity of substitution = 0.5
% of tasks automatable = 20
Agents cost $40/hour
In the maximally optimistic case, output grows at 19.3% per year on average over the next 20 years, and 16.3% per year over the next 100 years, although we think this is unlikely under purely cognitive automation for the reasons outlined above.
In our upper bound, output grows by 12.2% per year on average over the next 20 years, and 6.8% in the next 100 years.
In our lower bound, output grows by 3.5% per year on average over the next 20 years, and 0.7% per year over the next 100 years.
But, now we need to introduce Baumol effects. If automation is better in some industries than others, say films, finance, and programming; there are diminishing returns to having ever-greater amounts of B2B SaaS in the world, and so as a result, prices will fall in the industries where we are producing lots of goods, and so those industries share of GDP will rise by less than expected. Because of how GDP is constructed, at least half of the growth that would have occurred, less Baumol effects, will occur but this still dampens output by a lot.
But now we need to introduce Engel effects. As automation increases productivity and income, people tend to shift their spending toward sectors like healthcare, education, and housing - areas that historically show slower productivity growth. This phenomenon, known as Engel effects, means that as societies become wealthier, an increasing share of spending goes to these slower-growing sectors. In the US over the past few decades, Engel and Baumol effects have reduced output growth by approximately 25% (not 25pp) compared to what it would be otherwise.
Taking these Engel effects into account, we estimate that economic growth will be 3% to 9% higher per year for the 20 years following significant AI automation. This range reflects both the potential for productivity gains in highly automatable sectors and the dampening effect of spending shifts toward sectors where automation gains may be more limited.
Conclusion
This quote from The Optimistic Thought Experiment on the nature of the dotcom bubble, provides a useful lens for thinking about the economic impact of AI (albeit if the 'doom’ perspective is a little strong).
It is often claimed that the mass delusion reached its peak in March 2000; but what if the opposite also were true, and this was in certain respects a peak of clarity? Perhaps with unprecedented clarity, at the market ’s peak investors and employees could see the farthest: They perceived that in the long run the Old Economy was surely doomed and believed that the New Economy, no matter what the risks, represented the only chance.
The fundamental thesis—that AI research output will be automated; that humanity will create ‘superintelligent’ systems; and that AI systems will do science that create greater and faster technological progress than humans could ever have done—will be borne out in the fullness of time. But this vision has to make contact with reality, and reality can act as a weird breaking mechanism: Meta wants to build AGI, but they couldn’t use a nuclear power plant for their datacentre, because of some rare bees.
These bits never make it in the sci-fi novels, and so it’s easy to see far into the future, but miss the (frankly bizarre) hurdles along the way.
AI will still be constrained by physical and institutional bottlenecks—drug development still requires clinical trials, chip fabs take years to build, lab experiments need physical space and technicians, and negotiations between people need to take place. Lots of cognitive tasks will be automated, in our view, quite quickly, but because of the requirements for human liability and often necessary complements between cognitive tasks and ‘embodied’ tasks, we anticipate knowledge workers will be augmented, not replaced. In some sense, it could feel like ‘a promotion for everyone’.
Over time, the growth effects will rise beyond our current view, but accounting for present bottlenecks we expect an annual growth boost from AI to be 3-9%—transformative, but not explosive.
Many thanks to Byrne Hobart, Mike Webb, Dan Carey, Jason Hausenloy, Phil Trammel, Oliver Jaffe, Olivia Benoit and Eduard Baryon for invaluable feedback and comments in the process of writing this piece.
Jovanovic & Rousseau (2005), General-Purpose Technologies
Crafts (2004), Steam as a General Purpose Technology
David (1991), The Dynamo and the Computer
Davidson (2023), What a Compute-Centric Framework Says About Takeoff Speeds
Erdil and Besiroglu (2024), Explosive growth from AI automation: A review of the arguments, Barnett (2025), The economic consequences of automating remote work, Hanson (1997), Economic Growth Given Machine Intelligence
Trammell and Korinek (2023), Economic growth under transformative AI
We don’t intend to suggest there is a single, monolithic view at AI labs, nor that everyone there will subscribe to the strongest version of this view, but we mean to sketch a perspective on the dominant intellectual paradigm which a large proportion of actors are operating in.
“For the rationalists of the eighteenth and nineteenth centuries, as well as for all those who consider themselves cosmopolitan today, this sort of hysterical talk about the end of the world was deemed to be the exclusive province of people who were either stupid or wicked or insane (although mostly just stupid). Scientific inculcation would replace religious indoctrination. Today, we no longer believe that Zeus will strike down errant humans with thunderbolts, and so we also can rest peacefully in the certain knowledge that there exists no god who will destroy the whole world.
And yet, if the truth were to be told, our slumber is not as peaceful as it once was. Beginning with the Great War in 1914, and accelerating after 1945, there has re-emerged an apocalyptic dimension to the modern world. In a strange way, however, this apocalyptic dimension has arisen from the very place that was meant to liberate us from antediluvian fears. This time around, in the year 2008, the end of the world is predicted by scientists and technologists.” — The Optimistic Thought Experiment, January 2008
However, bank tellers did decrease both as a fraction of bank employment and per branch.
These are known as the income effect and substitution effect, respectively.
Again, there could be many more here! These benchmarks, in the words of their creators, could be greatly improved upon! Please consider working on this.
While these tests are at a smaller sample, the solutions are not going to be found online (as may be the case with Kaggle) so the models have not seen these problems before, these problems are likely to be more reflective of what ML engineering looks like for researchers in AI labs, and there is more control over the environment which humans perform the tests in. There are benefits to both approaches.
Optimising a kernel for latency refers to modifying the core program code that interfaces between computer hardware and software to minimize the time delay between when an instruction is initiated and when it is completed, often involving careful tuning of memory access patterns, thread scheduling, and hardware-specific optimizations.
AI labs should be very sensitive to reputation, e.g. nobody wants to be known as the place where people work after Anthropic or Google or OAI rejected them. Whereas if your lab has a GPU shortage, it's fine—Nvidia doesn't make as many as the market will bear, and the academics you're hiring are used to an even more acute shortage, so your pitch to them is something like "I'm sorry to say you may be so unlucky as to only have 100x the resources you have right now. Wish we could do better!"
https://x.com/eladgil/status/1827521805755806107
Tokens have awful margins, and are impossible to price discriminate on. However, moving to other industries may be hard.
Our estimates are in line with Epoch AI’s estimate that “2 million H100 GPUs [their projected total demand for 2024] would consume only 5% of the 5nm node capacity”. The differences arise from our inclusion of 4nm and 3nm capacity, and our focus on just hyperscale customers.
Funding institutions could also respond in other ways - such as a greater reliance on personal networks, automated application assessment, etc in ways which change the funding landscape in other ways with ambiguous effects on output.
US GDP has been growing relatively well over the past 2 years, with 5 consecutive quarters of 0.5% productivity growth in the US vs only 2 quarters over all of 2015-2019 with this, a development which may be related to AI but is hard to disentangle from other factors at present.
This should be celebrated as an unequivocal good for the world—people will be able to consume much more healthcare, unlimited by the scarcity of appointments and long wait times if they are willing to consume online; and access to the world’s best medical care is democratised to everyone in the world.
However, it has also been argued by some that advanced AI might succeed in effectively massively increasing worker skill levels by giving everyone VR access to inform the person what to do with their hands. This wouldn’t work with areas requiring trained dexterity (e.g. being a surgeon, violinist or top chef) but it could result in a reasonably high elasticity of substitution, at least for a while.
The paper he cites for the elasticity of 0.5 seems to be estimating an income elasticity rather than an elasticity of substitution, but we will follow.
There is one other potential use of these agents - intensifying research output. However, research plausibly faces the same problems regarding diminishing marginal returns to labour with the same capital stock. Additionally, ideas seem to be getting much harder to find over time, dampening the increase in research output from investing more resources in the sector further. In our calibration, a substantial majority of the gains from AGI went to lowering research intensity rather than raising output, hence we omitted it from the model as the effect on the results was small.
 | A guest post by
|
This chart (h/t Josh Yu) suggests OpenAI is spending comparable amounts on experimental compute as salaries. Also, the fact that they are leading despite less compute than Google means their lead could be attributed to better researcher talent. So not clear to me that researchers aren’t the bottleneck, especially if researcher skill is fat-tailed, which seems likely.
https://www.linkedin.com/posts/larsen-jensen_interesting-look-at-openais-projected-2024-activity-7250520525989380096-agmd/
> Lots of knowledge work bundles cognitive capabilities with ‘embodied’ human skills, for example, product management, consulting, medical care, and law. We think humans will continue to do these jobs, because whilst the cognitive capabilities could be in-principle automated by AI; they are complemented by things which AIs will struggle to do, at least in the near term. Be charismatic, be empathetic, be ‘present’, be accountable. (Perhaps there is a vision for robotics whereby close mimicry of human emotion and embodiment is possible, though we exempt this from our analysis.)
I am really unsure regarding charisma, presence and empathy. I think there was this paper from Google saying that people rate lm advice via text as more empathetic than from docs. I think it won't be too long till we'll have hyper realistic avatars indistinguishable from humans. So I suspect that non procedural medical jobs like psychiatry are at risk soon. In general I am uncertain if there will be a strong preference for humans simply because we won't be able to tell the difference