


The uphill battle to “mitigate the risks”
The EU's Code of Practice reveals we're all unsure how to regulate AI.

The go-to slogan for AI aficionados—and the tagline of this very magazine—is that we should "capture the benefits, and mitigate the risks". Its essential qualities are, one, that it acknowledges pros and cons, but, two, is sufficiently abstract that everyone can assign their own meaning. We all agree!
At some point, it would be preferable to have more concrete consensus on what we actually believe. The CEOs from the three leading labs have said extinction risk from AI should be treated on par with “other societal-scale risks such as pandemics and nuclear war” and all the labs have established frontier safety frameworks. Now comes the EU’s clarification: the third draft of their Code of Practice was released last week. This will implement the general-purpose aspects of the EU AI Act, passed this time last year.
Reading the draft is pleasantly surprising. There are no crazy requirements that caricatures of EU digital regulation might imply. On the surface, each request seems fairly sensible. However, once again, it has deferred the toughest questions. So often, the requirements are set as “appropriate” rather than specified. In the Safety and Security section, the word appears 107 times. Who will decide what this means?
There is a saying that in a democracy, a government must be satisfied that any laws they make can be enforced by their opponent. Perhaps there is a corollary here: if one writes “appropriate requirements” in an EU implementation document, they must be satisfied with the definition being set, not by the talented authors of the Code, but by a junior Brussels technocrat. The same kind who specified a training compute threshold of 1e25 FLOP in the original Act.
While the option value of flexibility might be preferable in the short term, this cedes too much power to the regulator and creates too much uncertainty for labs in the future.
This is clear in the section on systemic risk requirements. At a high level, these requirements are aiming to say, “If we observe this [sign of a bad thing], then we can [pull this handle].” This might mean, “If the model shows evidence of deceiving us as to its true intentions, we can pause training and investigate”, or “If the model helps a novice do harmful synthetic biology 5 times faster than they would be able to just Googling, we would harden lab security before continuing training, and improve model robustness, before deploying”. All reasonable requests. The challenge, however, is that we are leaving the regime where it was cheap—both in computational resources and time—to elicit model capabilities.
To look at this concretely, the Code of Practice requires:
[Signatories shall]
assess and, as necessary, mitigate systemic risks at appropriate milestones that are defined and documented before training starts, where systemic risks stemming from the model in training could materially increase, such as:
training compute based milestones (e.g. every two- to four-fold increase in effective compute);
development process based milestones (e.g.: during or after phases of fine-tuning or reinforcement-learning; before granting more individuals access to the model; or before granting the model more affordances such as network, internet, or hardware access); or
metrics based milestones (e.g. at predetermined levels of training loss or evaluation performance)
implement appropriate procedures to identify substantial changes in systemic risks which warrant pausing development to conduct further systemic risk assessment, such as automated benchmarks enabling a highly scalable and real-time identification of capability increases thereby lowering the risk of human or organisational bottlenecks.
[emphasis mine]
For older models, we can use ‘proof by non-example’: run GPT-3, ask it multiple-choice biology questions, see that it isn’t good enough to help with synthetic biology compared to just browsing the Internet, and, by induction, it is safe to deploy. This is also very cheap! Getting the model to answer these questions does not cost much, and the computer can handle the marking too.
This cannot be the case forever. Take this example: using Claude 3.5 Sonnet, a college student built a nuclear fusor in his kitchen in 36 hours. While this is not actually that dangerous—most of the information is Google-able—it is a toy example that demonstrates the kind of ‘human uplift’ we might care to study. “How much support does a model provide novices doing engineering tasks that might take days unassisted?”
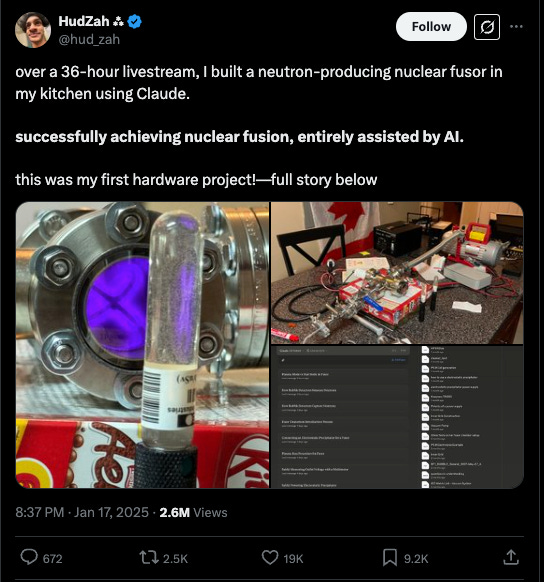
Applying the EU’s rules for systemic risk to this example, would we have to stop training the model at multiple milestones—“appropriate”, as determined by the regulator—and see how much faster it helps a novice to make a nuclear fusor? The rules say it is permissible to use automated benchmarks, but there aren’t any automated tests that could answer this.
It would only be possible to show a multiple-choice score from a set of questions about nuclear fusors, that boils down to, “this model knows a lot about nuclear fusors”. From this score, the researcher’s reactions would be unremarkable. Of course the model picked up knowledge about this, the models are good at memorising the Internet. And second, a high score on this benchmark is slightly meaningless: I don’t expect it would cause anyone to actually stop training to take mitigations.
Therefore, what would cause someone to stop training? Do we have to run red teaming at each milestone, with a new college student each time trying to build a nuclear fusor as quickly as they can? Is there an in-between, where we can create a series of tasks or environments that simulate aspects of aiding a human with this task? (This all assumes that we could foresee that we’d need to evaluate this capability, but some capabilities can make discontinuous progress. Imagine you’d be planning coding evaluations for the state of the art 12 months ago, it seems quite likely you’d have undershot model capabilities. I am speculating but I don’t think we knew it’d be possible to make a nuclear fusor in 36 hours when Sonnet 3.5 was released.)
The second challenge for these interventions is how much more expensive they are in computation. As we’ve written previously, all the labs’ R&D will be compute-constrained, and so any compute dedicated to running evaluations is not running experiments. As multiple-choice questions become less useful, we will need to run more long-horizon tests. For example, “Can this system write an expert-level plan for building a nuclear fusor and correctly order the components online?”. For a good evaluation, the researchers would need to run this at quite a large scale, using perhaps 100 copies of the AI system. As before, it is difficult to interpret the results. Let’s say that just 6 copies are successfully able to order the components and all the others made a mistake, or got stuck in a loop, or something else. Should we pause training then to take an intervention? What about if 60 copies succeeded? Surely this standard would differ for internal deployment, and deploying to hundreds of millions of people?
There is a similar problem with evaluating deception during training. Some people believe that the model might conceal its true intentions, reporting that it will be faithful to the values and rules it is taught in training but then rebelling later in training or deployment. (Others don’t think that this kind of ‘loss of control’ risk is possible.) We only have one evaluation for this capability, from Apollo. This gives the model a system prompt, and later exposes the developer’s true goals to the model, which conflict with the system prompt. The test evaluates whether the models continue with their original goal or follow the developer’s true goals. While valuable, this will not be able to provide the kind of conclusive evidence that would cause a lab to pause their training.
Later, the Code requires that before models are deployed:
“model evaluations are performed…proportionate to the systemic risk assessed to: (1) elicit the upper limit of current and reasonably foreseeable capabilities… [and] 4) match the realistic model elicitation capabilities of potential misuse actors”
“The given time shall be proportionate to: (a) the magnitude of the systemic risk assessed…An assessment time of at least 20 business days could, e.g., indicate that model evaluation teams were given enough time for most systemic risks and model evaluation methods.”
None of this is objectionable, but it is impossible to satisfy these conditions without making organisational overhead go through the roof! Internal teams, under these rules, would need to elicit the full extent of cyber offence capabilities; chemical, biological, radiological, nuclear capabilities; the potential for harmful manipulation; and the potential for loss of control. And for some of these capabilities, it does not mean just interacting with the model as it is, but with extra scaffolding too. That’s a lot to do in 20 days before deployment! Third party evaluators are given just seven days' access before deployment. It also seems difficult to imagine them having enough time to elicit the full extent of the model’s capabilities.
This is a version of the ‘jeep problem’: the further the jeep goes into the desert, the more fuel it needs to carry, but to deal with its heavier weight it needs to take more fuel. At some point, this becomes prohibitive to going any further! Likewise, as the models get more capable, the range of their dangerous capabilities gets wider (they could do more things) and longer (they are more useful for longer periods), so more and more compute and evaluation time is required, until it causes training to grind to a halt.
In some ways, the vagueness of the Code reveals a deep truth: there is not a suitable toolkit to regulate AI development yet. The current proof-by-non-example regime is going to run out of steam, and we don’t have answers for what will come after. We have to solve for both constraints: training and deployment has to continue with minimal interruption, but we need to elicit the full risks of the models and put in place safeguards. Answering these questions in this versions of the code could lock in an incorrect regime. Also, the EU can leave the door open for lenient enforcement, if they face pressure from the US, or to leave scope to enforce more stringently later.
To finish where we started: this doesn’t seem like a worthwhile trade. The Code of Practice cedes almost complete power to the EU AI Office to decide what is “appropriate”. They could be pausing training very often for extremely long tests to confirm it is safe to continue. This kind of error is the same as killed nuclear power: the International Commission for Radiological Protection has principles to be “precautionary” and “prudent” but this is poorly specified and has cascaded through the regulatory states’ poor incentives in the UK and the US. Now, the UK over-regulates radiation by a factor of 100 and struggles to build new power stations in 25 years. The same cannot happen to AI.
While the authors of the Code are well-meaning, and genuinely proportionate, the standard we should judge the code to is whether the junior official who will implement these rules in 2, 5, or 25 years time will do so with the same spirit. The constraints on the authors are enormous: satisfying proportionate constraints on training, against an immature scientific discipline for eliciting dangerous capabilities, and balancing the geopolitical headwinds that EU enforcement faces. These challenges, however, cannot justify complete discretion to the AI Office.