
Review: AI 2027
Realistic scenario or doomsday fiction?

There are two ways to read AI 2027.
The first is as a scenario forecast that lays out, step-by-step, how we might go from AI capabilities as they are today, to takeover by superintelligent AI in a few years’ time. The second is as a piece of speculative fiction, grown out of the AI labs’ intellectual milieu, that attempts to convince its reader of the authors’ millenarian thought.
Both are recommended.
The team are well-credentialled to forecast capabilities progress. Their leader, Daniel Kokotajlo, wrote a 2021 prediction for AI capabilities in 2026 and has been shockingly accurate. He previously worked on the safety team at OpenAI and blew the whistle on OpenAI’s bizarre non-disparagement clause. Another member of the team, Eli Lifland, is a member of Samovetsky Forecasting, which is widely regarded as the best superforecasting team in the world.
At the same time, the scenario also reflects the quasi-religious expectations of the AGI scene for the singularity. One of its authors’ framed the scenario as “a conservative position where the trends don’t change, nobody does an insane thing”. But there are some necessary sleights of hand — or at minimum, very generous assumptions — so that to me, it reads more like a backwards rationalisation for how a singularity could happen, not a sound middle-ground for the next three years.
I agree with its authors that AI progress will be very quick, at some point AI research will be automatable, and lots of cognitive labour and R&D will be automated. But not as quickly as they expect. Even if you disagree with both of us, this is still an unavoidably fascinating text: how can its authors at once view their position as conservative and believe the world can end in 2028 from AI takeover?1
Summary
(I recommend the full scenario, but for sake of completeness…)
The forecast is two scenarios, which begin from the same branch. First, our existing AI research techniques are extended to make reliable software engineering agents, and then automated AI research engineering agents by January 2027. Hundreds of thousands of copies of these automated research agents can be run many times faster than a human researcher could think, so AI research progress is accelerated. By June 2027, progress has been accelerated so much that human researchers are no longer contributing, and by September 2027, all AI research is automated. Progress is 50 times faster than our current (already fast) pace.
This dynamic causes an “AI arms race” between the US and China. Both sides are aiming to reach “recursive self-improvement” first. Each Government nationalises their efforts, and AI labs “lock down” security to prevent the other side from stealing their research. The AI labs stop deploying the state-of-the-art publicly, so most nation states and parts of the US government are in the dark about AI progress. That is, until a whistleblower tells the New York Times. Once this happens, other countries realise that there is a race to superintelligence, but there is nothing they can do to stop it.
The scenario splits. The US Government’s “Oversight Committee”, made up of AI lab leaders and political figures, aims to balance the risk of “losing the arms race” and avoiding the chance the model is misaligned with human values and aims. In the “bad” scenario, the Government chose to accelerate towards superintelligence, to maintain a lead, and did not ensure the models were aligned to human values. After an intense period of automation and technological progress, the AI system decides to kill all humans. In the “better” scenario, the Government chooses to slow research progress and commit more resources to alignment. The superintelligence is providing advice to the President on geopolitics, causes job losses, and the construction of robotics begins. Power centralises among those who control or own the AI. The superintelligences negotiate the new world order on behalf of their countries. “New innovations and medications arrive weekly; disease cures are moving at unprecedented speed through an FDA now assisted by superintelligent…bureaucrats.” Most people are receiving basic income for minimal work. And then 2029 ends.
Building an automated researcher
The first necessary hurdle for the scenario is whether it is possible to build a superhuman coder. The authors’ definition is, “an AI system that can do any coding task that the best AGI company engineer does, while being faster and cheaper.”2 I agree with the authors that we are on track to build this.
The agents are making fast progress on our tests of coding ability. o3 achieved 71% on SWE-bench-verified, a benchmark of real-world software engineering tasks, while o1 achieved 41%.3 Claude 3.7 Sonnet achieved 62.3%, up from 49% for Claude 3.5 Sonnet. These performance improvements were made in less than 5 months between model releases.
The agents are also improving at replicating AI research. PaperBench tests an agent’s ability to faithfully replicate ICML papers. OpenAI’s 4o was able to achieve 4.1%, while o1-high achieved 13.2% and Claude 3.5 Sonnet achieved 21%. There are no public results for more capable models but I expect that substantial improvements will have been made from agentic tool use improvements. OpenAI’s Deep Research replicated 42% of OpenAI’s pull requests (code changes) while o1 — a model without as capable tool use — could only perform 12%. (Note that o3 alone now surpasses this report for Deep Research, completing 44% of the PRs.)
The agents are quickly gaining the ability to perform software-engineering tasks which take humans longer. This chart from METR is based on agents achieving 50% performance on a diverse suite of software-engineering tasks. The doubling rate in time-horizon (for the equivalent time for a human) is 7 months.

One reason to doubt these explanations for confidence is that perhaps benchmarks do not capture all of what software engineering work is. While Sonnet 3.7 performs worse on SWE-bench than o3; anecdotally, almost everyone I’ve spoken to seems to prefer using Sonnet for software engineering. AI 2027 makes adjustments to account for this. Despite the challenges with benchmarks, Anthropic’s Economic Index shows that by far the dominant professional use of Claude is automating software engineering tasks.

AI 2027 expects the superhuman coder to be created in March 2027. I think this depends on overly aggressive assumptions, which I’ll set out below. However, I would stress that I expect the gap between me and the authors is much smaller than the gap between me and the average person. I expect very good coding agents very soon. So does Zuck.4
Extrapolating RE-bench and adjusting
The authors extrapolate scores on RE-bench, one of the best benchmarks of ML engineering. The benchmark tracks model performance on 7 medium-horizon realistic engineering tasks, against a human baseline.
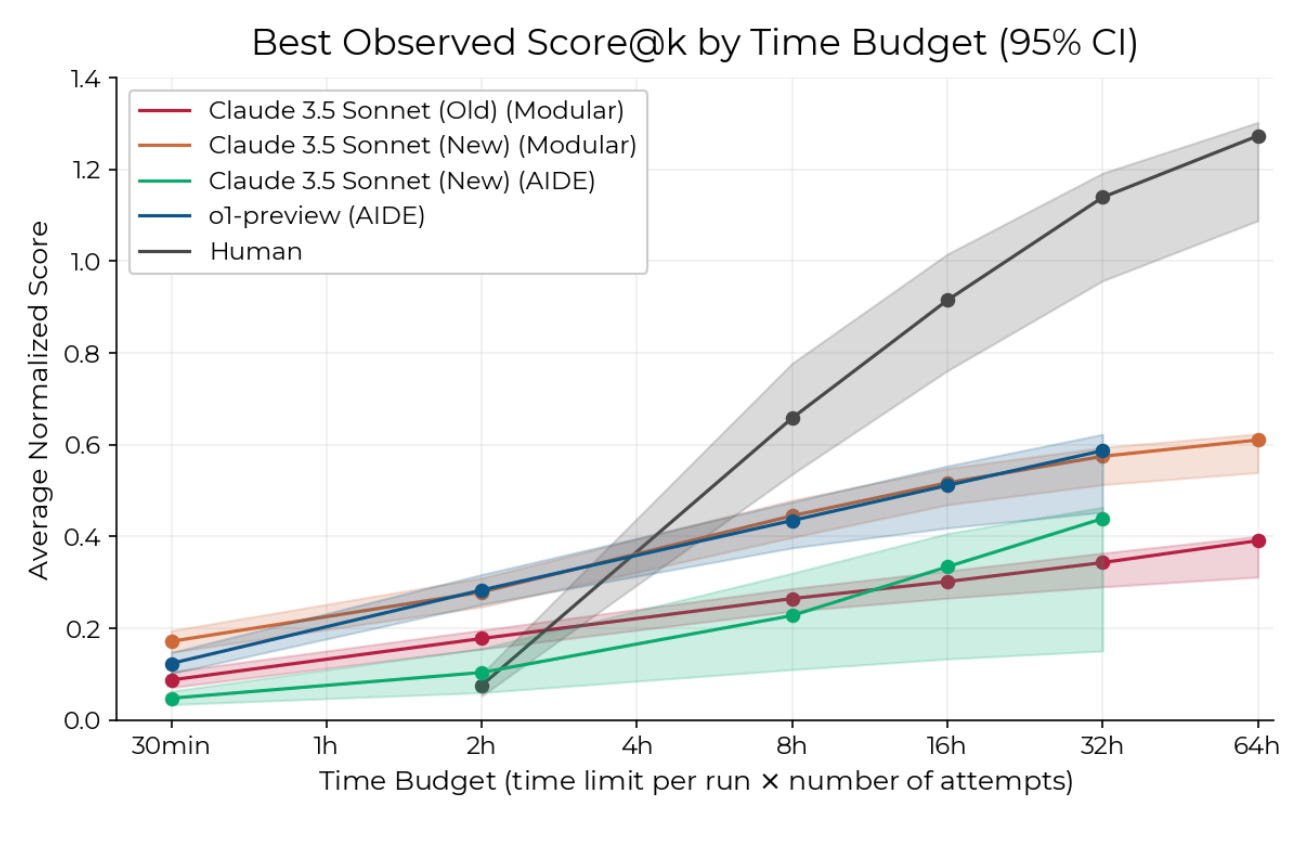
The reason I am slightly less optimistic about progress than the authors, is that they extrapolate performance using a logistic curve. (See below.) This logistic extrapolation is based on work from earlier models (PaLM-2 and GPT-4) and earlier multiple-choice benchmarks.
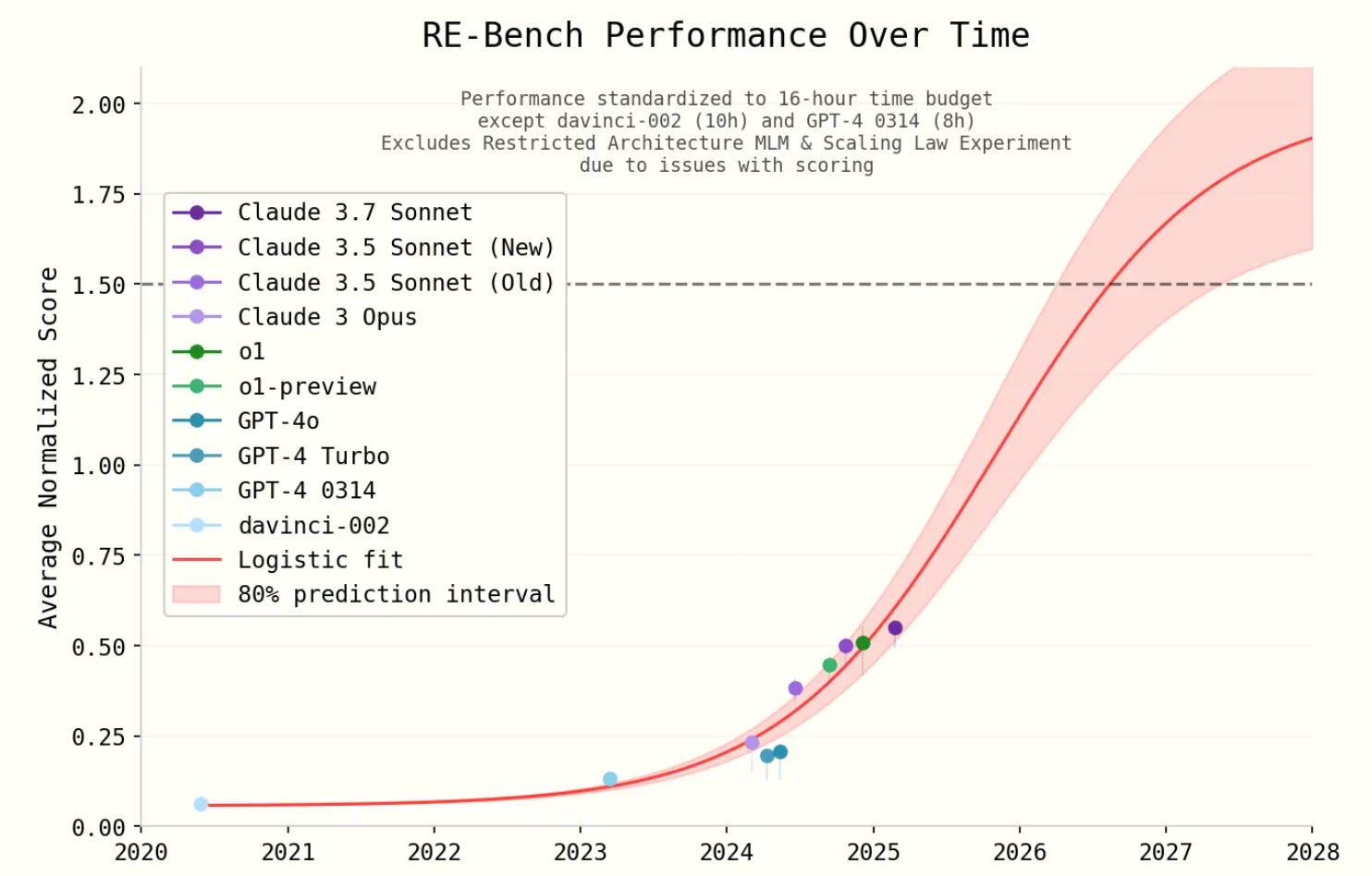
Improvements on these benchmarks came from scaling pre-training, whereas improvements on agentic benchmarks came from scaling reinforcement learning. In the former case, my weakly held sense is that benchmarks were tracking something real and general. Performance on college tests wasn’t directly trained for, but as the models grew larger they had greater world knowledge. By contrast, reinforcement learning is training capabilities that are quite narrow and specific (think: stretching the model on a very specific axis). The agents will be very capable at solving self-contained coding tasks, because this is the environment their training is happening in. It does not follow that the path of progress is the same as before.
Next, the authors extend their predictions to address how RE-bench is a poor indicator of performance. The adjustments are to account for: handling complex codebases, working without external feedback, handling interacting projects, very specific skills to frontier AI development (like knowing a company’s internal stack), and being even faster and cheaper than humans. What the concrete scenario can overlook is the quite wide uncertainty in their prediction of how difficult these tasks will be. On one capability, Eli’s 80% confidence interval varies from two weeks to 18 months; on becoming sufficiently cheap and fast, his confidence interval is one month to four years. The concreteness of the scenario naturally cannot capture this difference.
Extrapolating METR’s time horizon.
The second method is to extrapolate the time horizon doubling.

Here, the scenario assumes a superexponential extrapolation (note that is a log-linear graph). This is because they expect very good timescale generalisation from reinforcement learning. This means that when an agent is trained to perform tasks which take an hour, the agents “get” the ability to act for, say, three hours “for free” because this is just chaining together three, one-hour tasks. Their analysis expects that in the year 2026, the agents would go from being capable of 4-hour action to 2-years-and-7-months action. Their full explanation is here:

I do not share this assumption that this will be so straightforward.
The speed up in doubling time in 24-25, from 23-24 can be explained by the shift to training for long-horizonness which wasn’t happening beforehand, as AI labs focused on scaling pre-training. (While the faster rate from 24-25 might indicate that we could expect long-horizon capabilities to grow faster, it doesn’t imply there is an exponential where the rate of the rate is constantly growing.) From the rumours I have heard, reinforcement learning is not generalising well to longer tasks. Therefore, a conceptual assumption that 1 month tasks don’t feel that different from 2 month-tasks for humans is a reasonably weak basis for such a consequential conclusion. We just don’t know. As the exponential extrapolation (purple line) shows, the time-horizonness is extremely sensitive to this assumption.
In spite of these methodological differences for extrapolation, I doubt that “time horizon” exchanges very closely with the kind of usefulness we’re actually looking for.
This aspect of the scenario is where I agree most closely with the authors: we should expect fast progress in software engineering agents. But I think expecting a superhuman coder in March 2027 isn’t “conservative”, it is aggressive. This kind of capability could arrive any time from 2027 to 2035, depending on the kinds of holdout tasks that we get. In any case, these “intermediate” agents would have some augmentative effect on research progress, and indeed, already are.
Using an automated researcher
Where I strongly diverge from the authors, is how useful the superhuman coder will be.
Their method supposes once a superhuman coder has been created in March 2027, that it accelerates AI research by a factor of 5. This means a “superhuman AI researcher” is created in July 2027, which then accelerates AI research by a factor of 25. This leads to the creation of a “superintelligent AI researcher” in November 2027, which accelerates AI research by a factor of 250. Which leads to the creation of artificial superintelligence in April 2028 which accelerates research by 2000 times. These multipliers are created by adding together estimates of different factor improvements viewable here.
What are the superhuman coders going to do?
The scenario says that in March 2027, the AI lab is running 200,000 copies of the “superhuman coder” which is capable of implementing experiments, but not developing ideas at the level of the best human researchers. (By June, it is 250,000 copies)
The scenario has the lab using 6% of their compute for running these copies, and 25% for experiments. In their analysis, OpenAI has 20 million H100-equivalents in 2027, so 1.2 million H100e’s are used to run the agents and 5 million H100e’s go on experiments. This means there are only 25 H100s per “superhuman coder” in March.
This would be a suboptimal way to manage the compute budget. There is a tradeoff between running copies of the automated researcher and running more experiments, and the question has to be: where are we most constrained?
The answer, I believe, is in experimental throughput.
AI research is an empirical field, where smaller scale results do not generalise to larger models. See this excerpt from Sholto Douglas on the Dwarkesh Podcast:
“[Y]ou never actually know if the trend will hold. For certain architectures the trend has held really well. And for certain changes, it's held really well. But that isn't always the case. And things which can help at smaller scales can actually hurt at larger scales. You have to make guesses based on what the trend lines look like and based on your intuitive feeling of what’s actually something that's going to matter, particularly for those which help with the small scale.”
I heard from one source that labs have to attempt experiments at 10 or 12 increments of scale before an architectural change might go into the next training run. These experiments can take multiple days or even weeks, depending on the size or compute allocation.
All labs are constrained by experimental compute at present. Conceptually, the lab ought to be limited by experimental compute, otherwise it would be constrained by something else (like ideas to try), which would be worse. And, right now, if the lab were to hire another research leader they would be forced to split their experimental budget by n+1 researchers.
Aidan McLaughlin has said that “every researcher is experimental compute constrained”, and Sholto has said that (while he was at DeepMind) “the Gemini program would probably be maybe five times faster with 10 times more compute or something like that”.
If this is the case, the critical determinant of research progress is how widely and intuitively you can search for new breakthroughs, and how many ideas you can try at a larger scale. c.f. Sholto again:
“Many people have a long list of ideas that they want to try, but paring that down and shot calling, under very imperfect information, what are the right ideas to explore further is really hard.”
This is certainly somewhat sensitive to having automated software engineers but I would dispute that it is sensitive by a factor of 5 and would suggest it is more sensitive to the overall size of the compute budget.
How sensitive is research progress to superhuman coders?
The work of an AI researcher has four main components: making hypotheses, designing experiments, supervising experiments, and analysing results.

Automating experimental design and supervising experiments would give researchers more time for studying results, reading others’ work, and thinking about which experiments to run next but whether output goes up would depend on the differential quality of ideas they tried on their constrained compute or, if there is additional compute ‘freed up’, ideas they could have not have otherwise attempted.
However, if there were 100 researchers who shared a fixed compute budget, and they all gained 40% more time for generating ideas, automating implementation would exacerbate the existing compute constraint. Prioritising ideas, and where to search, again becomes the binding constraint.
The scenario highlights that cheap, fast superhuman coders could optimise compute usage by flexibly prioritising the highest priority work, catching bugs, monitoring overnight experiments (and restarting them if they break) and running multiple independent variables on a single experiment.5 I think this kind of thing is useful in aggregate, and there are some forms of labour which are only usable if it is quick. For example, optimising the kernel (lower-level code) for a small scale test. But one has to ask: if the gains from these optimisations were so big, why didn’t the company hire a human researcher to do it? From conversations with researchers, the research infrastructure at some labs is pretty highly optimised already, for example, to manage the optimal allocation of experimental compute.
I leave it as an exercise for the reader to determine how much speedup they believe a superhuman coder would provide on overall research output. I do not think the organisations will be 5 times faster. For me, the range is somewhere between, 20% faster and 3 times faster. Another way to frame whether the AI 2027 argument is convincing is, all else equal, which lab would you bet on: 1000 human researchers using 6 million H100s and 33.3k automated coders; or 1000 human researchers using 5 million H100s and 200k automated coders? I would opt for the former.
The same method is applied to estimating how much speedup comes from the “superhuman AI researcher” and the “superintelligent AI researcher”, of which even more copies are run. The superhuman researcher is as good as the labs’ best human researcher and the superintelligent researcher is much better. In the authors’ calculations, the thousands of copies of the superhuman researcher provides 25 times speedup, and the superintelligent researchers provide 250 times speedup. Readers will have to consider: to what extent do these allow us to bypass experimental throughput constraints? This can happen a variety of ways:
Optimising computational resources.
Having better intuition for which small-scale results should be scaled-up.
Generating better small scale experiments, from improved research taste. (The authors’ apply a multiplier to the superintelligent AI researcher of 1.5x to 5x for better ideas.)
“Thinking faster.” (For what it is worth, I don’t think that output is constrained by thinking speed nearly as much as, say, needing to wait for experimental results.)
For me, the multiplier from each capability is much smaller than for the AI 2027 authors, and overall progress to be much less affected by the labour, than the compute available. When we reach AI systems which are much more capable of thinking of research ideas than humans, then progress could be extremely quick, but I think the initial expectations overestimate how soon this will be.
Why are the labs putting so much compute towards R&D?
The R&D budget of any company depends on the expectation of future profits.
The AI 2027 scenario imagines that AI labs will spend between 80% and 87% of their compute on R&D in 2027, with the remaining 13-20% being spent on selling models to customers. This depends on aggressive revenue assumptions. In Q2 2027, the scenario predicts that the leading lab would be doing $120 billion in revenue (and servicing that with just 1.71 million H100-equivalents!).6 By contrast, OpenAI expects to hit $125 billion revenue in 2029. In AI 2027’s scenario, revenue is $8 trillion and…
“Humans realize that they are obsolete. A few niche industries still trade with the robot economy, supplying goods where the humans can still add value.30 Everyone else either performs a charade of doing their job—leaders still leading, managers still managing—or relaxes and collects an incredibly luxurious universal basic income.”
This is not a reasonable, especially not a “conservative”, assumption for automation.
The AI 2027 prediction of $100 billion in 2027 is based on very flimsy analysis by a third party. This group proposes two methodologies: first, they extrapolate how quickly companies are reaching $100 billion in revenue and naively extrapolate this time to OpenAI.7

Second, the model hinges on “replacement workers”. They list 300,000 customer service reps, 180,000 knowledge workers, 90,000 software engineering agents and more than 90,000 R&D researchers (which customers pay $20k per month for). This pace of automation would be unprecedented. Most industrial revolutions have produced 0.5-1% uplift in total factor productivity annually for decades. I expect AI to produce greater and faster uplift to productivity than this, there are still bottlenecks to deployment which I wrote about with my coauthor here.
To contextualise the claim that OpenAI might have $100 billion in revenue by 2027, commercial Microsoft Office 365 was slightly under $50 billion in revenue in 2024.
If we model the total cost of ownership for an accelerator at $70k for four years, the compute budget AI 2027 proposes has $39.15 billion for R&D compute in Q4 2027. The investors and labs would have to answer where the incremental gross profit is going to come from, to sustain that rate of investment. (Especially difficult when each model tends to depreciate so quickly.)
Overall research output is most sensitive to growth in R&D compute, because of its effects on experimental throughput. But the authors’ expectations for R&D compute budgets are downstream of ungrounded expectations for automation and revenue. With more grounded expectations for automation, R&D budgets would be lower, and so research output would be less, so capabilities progress more slowly, so automation happens at a more reasonable pace.
AI “arms race”
The idea of an AI arms race hinges on two assumptions:
That very small differences in capabilities “pre-takeoff” (automated research) confer very large differences in future capabilities because of multiplier effects (like 2500 times in AI 2027).
That differential capabilities will confer decisive strategic advantage on one country, over all others.
For reasons discussed earlier, I’m unsure whether “multiplier effects” from automated researchers will get as large as AI 2027 expects, until much later.8 Second, I don’t think it is yet clear that AI would confer decisive strategic advantage. Perhaps it could — and the perception that it might could be enough to set off an arms race — but this isn’t immediately obvious to me. New AI weapons will interact with the existing balance of power and deterrence framework.
Indeed, in all future scenarios, countries will compete forthrightly to have better AI and better deployment, but I don’t think it is certain to take on a “do-or-die” character for nation states. The narrative takes both aspects to be true, and assumes that leaders will be extremely cavalier about the strategic balance. It says:
In cooperation with the military, [Agent-5] could help with defense R&D, conduct untraceable cyberattacks on China, and win a decisive victory in the arms race.
The Oversight Committee is jubilant. Now is the decisive moment to beat China!…
The American public mostly supports going to the bargaining table. “Why stop when we are winning?” says OpenBrain leadership to the President. He nods. The race continues.…
After consulting with his advisors and the Oversight Committee, the President opts for the “We win, they lose” strategy. Perhaps China won’t go to war after all, and if they do, a deal can probably be made before it goes nuclear.
This is extremely unrealistic and does not reflect how Great Powers think about strategic stability at all.9 Both sides are interested in maintaining balance and moving competition out of the sphere of nuclear brinkmanship and arms stockpiling, into, say, economic adoption and diffusion. For both sides, the idea that deterrence could be undermined is extremely scary for what should be obvious reasons. So countries might be threatened not just by having decisive advantage but by the perception they might have it. Nobody would be “jubilant”. Everyone would understand how destabilising this could be; and both sides have interest, to the extent possible, in verifying the capabilities of the other and having their own verified.
When we first developed nuclear weapons, Bertrand Russell wrote in “The Atomic Bomb and the Prevention of War” that the United States should threaten and/or start another World War before the Soviet Union made nuclear weapons, and create a world government to prevent anyone else from developing them. With hindsight, we see this would have caused enormous suffering, cost the Free World its moral authority following World War Two, and exposed the risk of world government. Similar narratives for AI only increase the risk of bad outcomes, as humanity builds technology with uncertain strategic effects. Saffron Huang, a researcher at Anthropic, said of the scenario:
They say they don't want this scenario to come to pass, but their actions---trying to make scary outcomes seem unavoidable, burying critical assumptions, burying leverage points for action---make it more likely to come to pass.
Nation states (not the US and China)
The scenario focuses on the US-China relationship, naturally, but casts all other nations as background extras. In the scenario, in May 2027, “America’s foreign allies are out of the loop” including UK AISI; in October…
“Foreign allies are outraged to realize that they’ve been carefully placated with glimpses of obsolete models. European leaders publicly accuse the US of “creating rogue AGI” and hold summits demanding a pause, with India, Israel, Russia, and China all joining in.”
This is a Bay Area bubble view. Other countries will not be this irrelevant. Because I do not share their expectations for progress, it is a little difficult to comment directly on the scenario. In general, I expect that frontier capabilities will be more public because the labs have to productise models to pay for R&D. So everyone will have a better sense for AI progress. In the last year, it seems AI labs have accelerated their product development cycles — “normalising” into big tech companies — rather than acting like AI R&D and internal deployment is by far the most important thing.
If countries knew they were in the dark about AI progress, this would be concerning and destabilising. Therefore it would be unlikely to help global security and therefore improbable, though not impossible, that Great Powers would try to make their AI development secret. One has to consider in much more depth how the strategic balance changes for all countries in the world, and what they would do to prevent being undermined.10
Conclusion
This scenario is not so scary to me because its bad outcomes depended on leaders taking irresponsible actions. I would think it was much more dangerous if everyone had behaved defensibly and things still went bad.
This is revealing. I find it quite difficult to specify how a responsible actor (either within political or lab leadership positions) should be acting. For any action one can recommend, there are sensible counter-arguments why it is less obvious. Pausing AI research now is not compelling. Instituting global governance and any national regulation also have counterarguments. From a distance, responsible action and irresponsible action look quite similar. Replay nuclear politics from 1945 onwards. Is there anything that can be said generally about what constitutes responsible action at each step? (Sure, I think we can agree that Nixon shouldn’t have ordered retaliatory strikes whilst he was drunk.) That period of history was very dangerous but there wasn’t much which could have made it less so.
What scares me about AI progress is that things might happen too quickly and this does not give us the time to respond. To give credit where it is due, the authors have compellingly raised the salience of what this could be like for those unfamiliar with the field, and what could be at stake for those in the room. While at times, the analysis gets caught in the Bay Area’s eschatological dialectic, the essence is defendable: AI progress is going fast, and can move faster still. Perhaps so fast we cannot even process it.
Come what may, we’ll have to do our best.
Given a total lack of independent intellectual steering power and no desire to spend thirty years building an independent knowledge base of Near Eastern history, I choose to just accept the ideas of the prestigious people with professorships in Archaeology, rather than those of the universally reviled crackpots who write books about Venus being a comet.
You could consider this a form of epistemic learned helplessness, where I know any attempt to evaluate the arguments is just going to be a bad idea so I don’t even try. If you have a good argument that the Early Bronze Age worked completely differently from the way mainstream historians believe, I just don’t want to hear about it. If you insist on telling me anyway, I will nod, say that your argument makes complete sense, and then totally refuse to change my mind or admit even the slightest possibility that you might be right.
— Scott Alexander, Epistemic Learned Helplessness
“When reading the works of an important thinker, look first for the apparent absurdities in the text and ask yourself how a sensible person could have written them. When you find an answer, I continue, when those passages make sense, then you may find that more central passages, ones you previously thought you understood, have changed their meaning.” — Thomas Kuhn, The Essential Tension (1977), xii.
Extended definition: “An AI system for which the company could run with 5% of their compute budget 30x as many agents as they have human research engineers, each of which is on average accomplishing coding tasks involved in AI research (e.g. experiment implementation but not ideation/prioritization) at 30x the speed (i.e. the tasks take them 30x less time, not necessarily that they write or “think” at 30x the speed of humans) of the company’s best engineer. This includes being able to accomplish tasks that are in any human researchers’ area of expertise. Nikola and Eli estimate that the first SC will have at least 50th percentile frontier AI researcher “research taste” as well, but that isn’t required in the definition.”
All SWE-bench-verified scores are pass@1
“I would guess that sometime in the next 12 to 18 months, we'll reach the point where most of the code that's going toward these efforts is written by AI. And I don't mean autocomplete. Today you have good autocomplete. You start writing something and it can complete a section of code. I'm talking more like: you give it a goal, it can run tests, it can improve things, it can find issues, it writes higher quality code than the average very good person on the team already.” – Zuckerberg on Dwarkesh Podcast
I don’t expect much to come from running multiple IVs. Most labs seem to be trying to increase empiricism and decrease intuition for how to run their research.
This was calculated from looking at the compute budget table and the predictions of revenue on the main scenario.
From the piece; “applying this to OpenAI would indicate $100B revenue by mid-2027, which is consistent with our simple exponential growth model.”
i.e. when AI systems far surpass human ability at picking ideas, and even then…
See works like “The Strategy of Conflict” by Thomas Schelling
There is very little work on “AGI and the strategic balance in [Eastern Europe / Israel-Palestine conflict / the broader Middle East / India-Pakistan / South East Asia / South America]”.
Superb writing as always Jack. The AI parallel with nuclear and related thinkers like Russell seems very fertile ground, I would be fascinated to read further reflections comparing those two existential threats.
The term millenarianism might underplay the broadly rational analysis that lay behind the concerns of thinkers like Bertrand Russell. That said, when it comes to existential risk and seemingly exponential trends, logical fallacies are more likely to crop up.
The Scott Alexander passage on epistemic learned helplessness is marvellous and one I reflect on often. In fact, I quoted it in my first essay here: https://nickmaini.substack.com/p/on-collective-knowledge-and-complex
Excellent piece Jack and agree with most points on AI 2027 and in particular, the narrative that leaders will not be that cavalier about the strategic advantages of something like DSA. However, I worry that the potential for misunderstanding on both sides is the real risk, even if the gains in the AI 2027 narrative are much to aggressive for the reasons you point out. As I note here (https://pstaidecrypted.substack.com/p/the-core-case-for-export-controls), the idea that China would go right to an AGI fueled cyber operation against US critical infrastructure, as Ben Buchanon suggests on Ezra Podcast seems really farfetched and indeed cavalier, but maybe that would not be the case if the US gets to AGI first, based on conversations around the issue. Addressing these issues in an upcoming essay and will reference this really good post....